Human-Centric Federated Learning
Federated Learning (FL) is a Machine Learning (ML) paradigm proposed to implement privacy-by-design. Using data-driven methods for Artificial Intelligence (AI) applications raises questions about data privacy and security. Countries try to address these questions and proposed laws to prevent the misuse of data, for example, the EU leading the field with the GDPR.
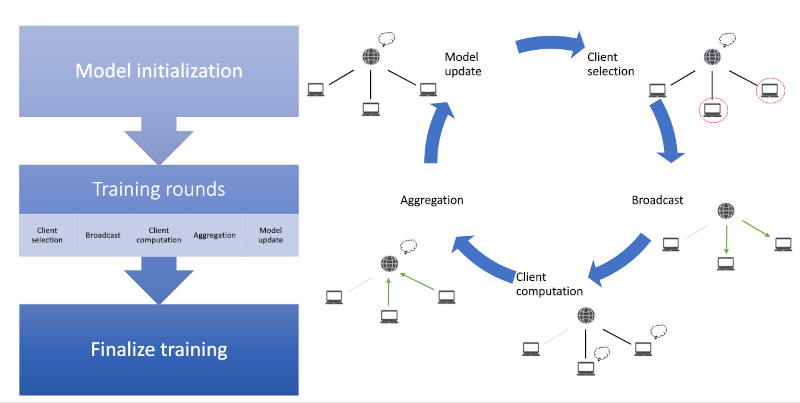
In concept, FL proposes to solve this issue by design. In FL, the clients (eg. hospitals) hold the data and it never leaves their computer. The server (eg. AI company) only manages the collaborative learning and aggregates local results. In a training round in FL, the clients train their local model based on their private data, they send the model parameters to the server and the server aggregates them to generate one global model. Then, the server can send this updated model back to the clients so the clients can benefit from the knowledge of the other participants. FL is also useful for personalization because if the model and data are already at the client side, fine-tuning the received global model on the personal data is the same process as it is done during the federated training.
The figure below shows a vanilla federated learning scenario. Steps of a training round in FL:
Client selection, Broadcast, Client computation, Aggregation, Model update
Research questions
In our lab, we are trying to understand federated learning from a human perspective. Imagine you are using a smartphone keyboard with next-word prediction and the application says they are using federated learning to give better predictions. What does it mean? When should someone opt-in or opt out of federated learning?
Federated Learning is always a trade-off between privacy and accuracy: if one has enough data to train a good model locally, that can achieve perfect privacy and if one wants the best accuracy, fully centralized learning is the best approach.
1. Understanding participation
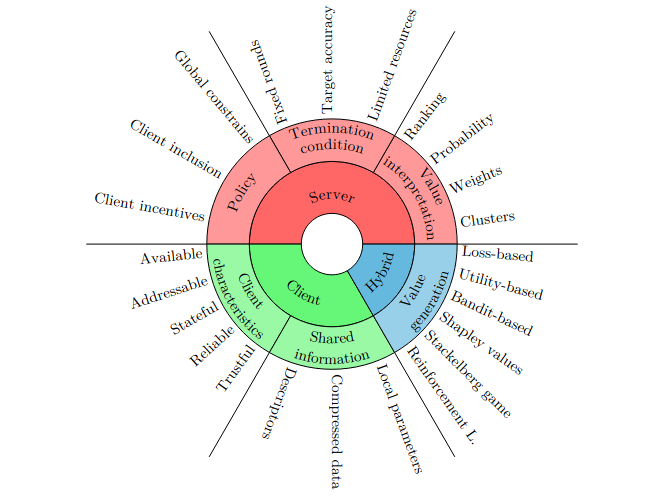
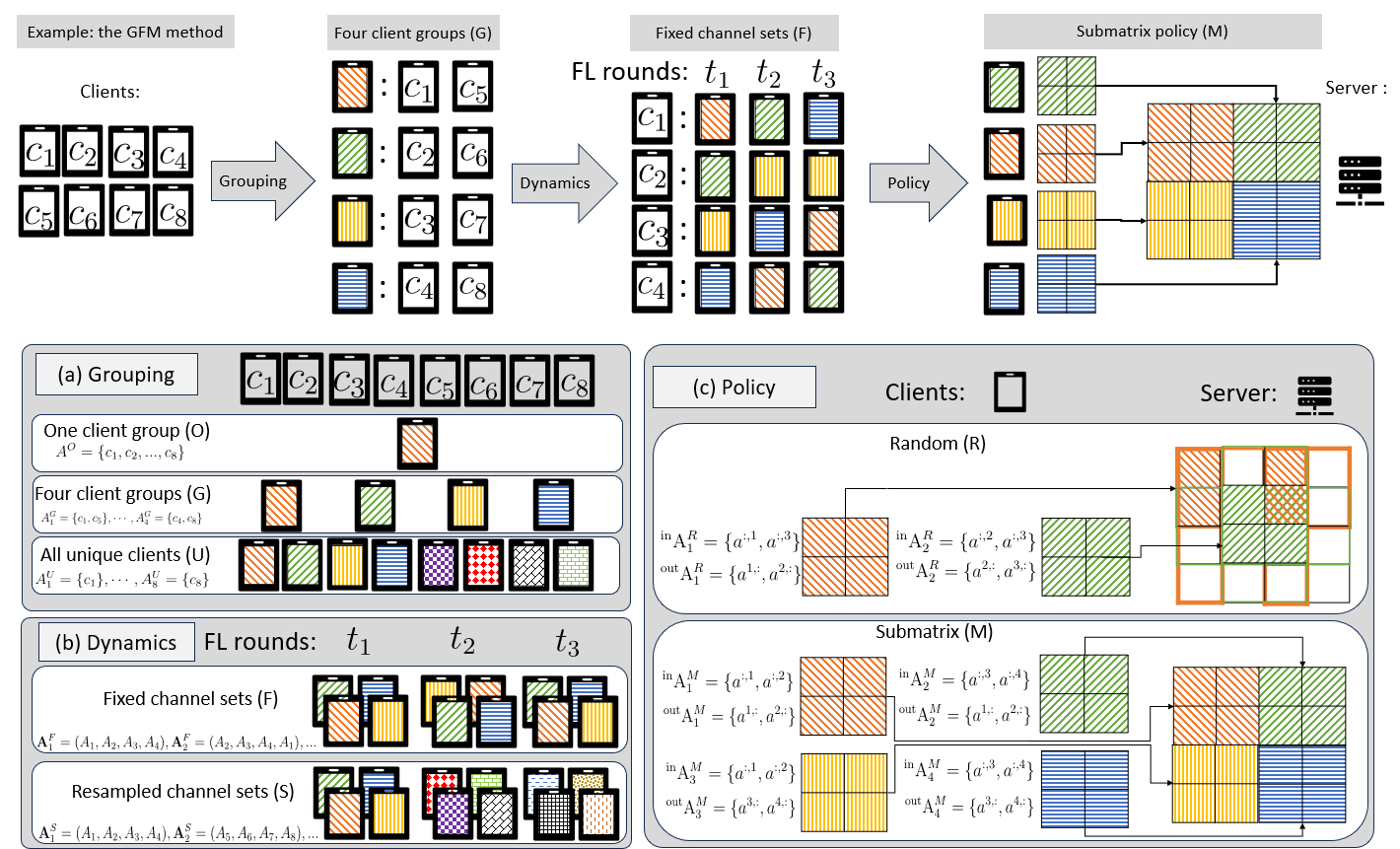
In this area, we are focusing on client selection and client participation. From the server's perspective, which ones are the important clients? From the client's perspective, when should they participate? And how to use incentives to motivate the clients to participate?
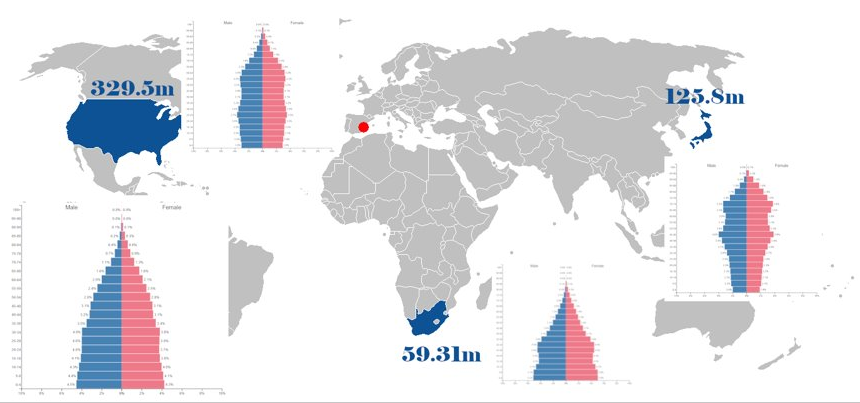
Another example is the day/night shift. Imagine a scenario where a keyboard application builds a next-word predictor in a federated way using the smartphones of users from around the world. Let's say that we collect the client updates on a server located in Alicante and we end a training round at noon every day. We will have fewer responses from Los Angeles (US) than if we would end it at midnight. Why? Because to train a model without distracting the user, the smartphone has to be in an idle state, connected to WiFi and an electric outlet. Otherwise, it can drain the data quota or the battery of the device. But if we collect data at noon in Alicante, a city using the UTC+1 timezone, in Los Angeles the time is 4 am in the morning (UTC-7). Which is right in the middle of a regular sleeping time so clients in Los Angeles have only half of a night to finish their local training in time.
In this line of work, we analyze the biases and design algorithms to mitigate them.
Frequently Asked Questions
Federated Learning (FL) is a machine learning paradigm proposed by researchers at Google. In FL, clients train local models on private data, with collaboration to have a better global understanding of a problem, without sharing any sensitive information with each other or the coordinating server.
Client selection refers to the process in a federated training round when contributing clients are chosen from the total available ones.
A Federated Learning training usually comes with an initialization phase controlled by the server, several training rounds, and a finalization that can include personalization. A typical training round consists of Client selection, Broadcast, Client computation, Aggregation, and Model update
Day-shift / night-shift representation, Closer to server overrepresentation, Heavy users, Better devices, Potential users not represented
Our work in the media
Towards Data Science: From Centralized to Federated Learning
Our scientific publications
2025
Dubrovnik, HR