Aprendizaje Federado centrada en la humanidad
El Aprendizaje Federado o aprendizaje colaborativo (Federated Learning, FL) es un paradigma de Aprendizaje Automático (Machine Learning, ML) propuesto para implementar la privacidad por diseño. El uso de métodos basados en datos para aplicaciones de Inteligencia Artificial (IA) plantea interrogantes sobre la privacidad y seguridad de los datos. Los países intentan abordar estas preguntas y proponen leyes para prevenir el mal uso de los datos, como la Unión Europea liderando el campo con el Reglamento General de Protección de Datos (GDPR).
En concepto, el FL propone resolver esta cuestión mediante el diseño. En el FL, los clientes, o nodos (por ejemplo, hospitales) tienen los datos y nunca salen de sus computadoras. El servidor (por ejemplo, una empresa de IA) solo gestiona el aprendizaje colaborativo y agrega los resultados locales. En una ronda de entrenamiento en el FL, los clientes entrenan su modelo local basado en sus datos privados, envían los parámetros del modelo al servidor y el servidor los agrega para generar un modelo global. Luego, el servidor puede enviar este modelo actualizado a los clientes para que puedan beneficiarse del conocimiento de los demás participantes. El FL también es útil para la personalización porque si el modelo y los datos ya están en el lado del cliente, ajustar el modelo global recibido a los datos personales es el mismo proceso que se realiza durante el entrenamiento federado.
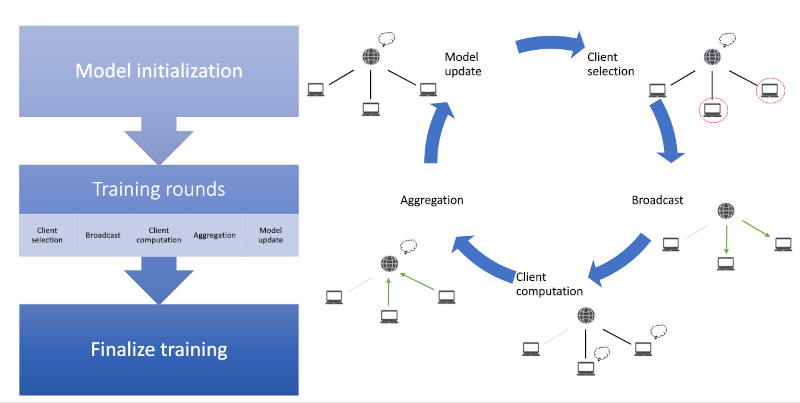
La figura siguiente muestra un escenario de aprendizaje federado convencional. Pasos de una ronda de entrenamiento en el FL:
Selección de los clientes, Transmisión, Cálculo de los clientes, Agregación, Actualización del modelo
Preguntas de Investigación
En nuestro laboratorio intentamos comprender el aprendizaje federado desde una perspectiva humana. Imagina que utilizas el teclado de un smartphone con predicción de palabras y la aplicación dice que utiliza el aprendizaje federado para ofrecer mejores predicciones. ¿Qué significa esto? ¿Cuándo debería alguien optar por participar o no en el aprendizaje federado?
El Aprendizaje Federado es siempre un compromiso entre privacidad y precisión: si se tienen suficientes datos para entrenar un buen modelo local, se puede conseguir una privacidad perfecta, y si se quiere la mejor precisión, el aprendizaje completamente centralizado es el mejor enfoque.
1. Comprender la participación
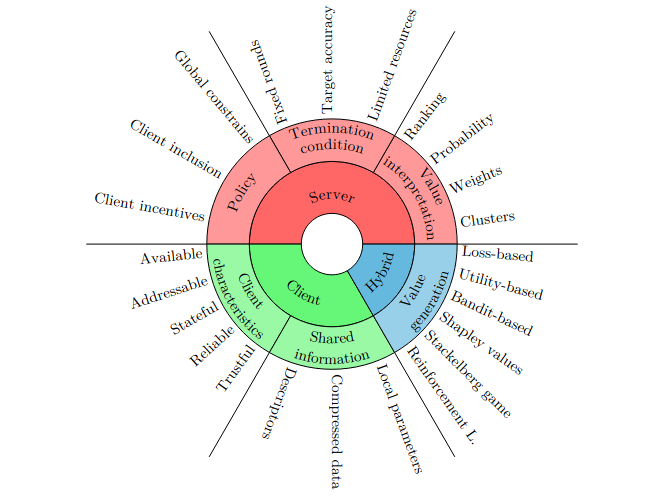
En este contexto, nos centramos en la selección o participación de los clientes. Para el servidor, ¿cuáles son los clientes importantes? Y desde la perspectiva del cliente, ¿cuándo deberían participar? ¿Y cómo utilizar incentivos para motivar a los clientes a participar?
2. Comprender la privacidad
A pesar del diseño del Aprendizaje Federado, todavía es posible filtrar información privada a través de la memorización del modelo. En esta línea de trabajo, nos enfocamos en comprender la privacidad en el FL y proponemos métodos de preservación de la privacidad para defender el FL contra ataques a la privacidad.
La distribución de los datos en el aprendizaje federado tiene un gran impacto en el resultado, en términos de rendimiento, privacidad y equidad. El enfoque actual para mitigarlo consiste en construir mejores optimizadores que sean robustos frente a los problemas que surgen con datos que no están idistribuidos de forma idéntica e independiente (IID). Sin embargo, para que un cliente comprenda las ventajas e inconvenientes de participar en FL, queremos abordar este reto a priori. La pregunta de investigación de este proyecto es ¿Qué podemos esperar del FL a partir de nuestro conocimiento sobre la distribución de los datos?
4. Comprender la Equidad Algorítmica en el Aprendizaje Federado
El aprendizaje federado puede ser fuente de nuevos sesgos. Como los datos no están IID, es probable que aumente la infrarrepresentación de determinados grupos demográficos. Pero esto es sólo el comienzo del problema. Dado que los clientes tienen acceso a distintos niveles de potencia de cálculo y ancho de banda de comunicación, si las actualizaciones se manejan tal y como se reciben en el lado del servidor, los clientes más potentes tendrán una mejor representación.
Otro ejemplo es el turno día/noche. Imagina un escenario en el que una aplicación de teclado construye un predictor de palabras siguientes de manera federada utilizando los teléfonos inteligentes de usuarios de todo el mundo. Supongamos que recopilamos las actualizaciones de clientes en un servidor ubicado en Alicante y terminamos una ronda de entrenamiento al mediodía todos los días. Tendremos menos respuestas de Los Ángeles (EE. UU.) que si termináramos a medianoche. ¿Por qué? Porque para entrenar un modelo sin distraer al usuario, el teléfono inteligente debe estar en estado de reposo, conectado a WiFi y a una toma de corriente. De lo contrario, puede agotar la cuota de datos o la batería del dispositivo. Pero si recopilamos datos al mediodía en Alicante, una ciudad que utiliza la zona horaria UTC+1, en Los Ángeles serán las 4 de la mañana (UTC-7). Que está justo en medio de un horario de sueño regular, por lo que los clientes en Los Ángeles tienen solo la mitad de la noche para completar su entrenamiento local a tiempo.
En esta línea de investigación, analizamos los sesgos y diseñamos algoritmos para mitigarlos.
Preguntas Frecuentes
El Aprendizaje Federado (Federated Learning, FL) es un paradigma de aprendizaje automático propuesto por investigadores de Google. En el FL, los clientes entrenan modelos locales con datos privados, colaborando para tener una mejor comprensión global de un problema, sin compartir información sensible entre sí ni con el servidor coordinador.
La selección de clientes se refiere al proceso en una ronda de entrenamiento federado en el que se eligen clientes que contribuirán de entre todos los disponibles.
Un entrenamiento de Aprendizaje Federado generalmente incluye una fase de inicialización controlada por el servidor, varias rondas de entrenamiento y una finalización que puede incluir la personalización. Una ronda de entrenamiento típica consta de selección de los clientes, transmisión, cálculo de los clientes, agregación y actualización del modelo.
Representación de turnos día/noche, Sobre representación de clientes más cercanos al servidor, Usuarios intensivos, Dispositivos de mayor calidad, Usuarios potenciales no representados.
Nuestro trabajo en los medios
Towards Data Science: From Centralized to Federated Learning
Nuestras publicaciones científicas
2025
Dubrovnik, HR