
La Historia de la Inteligencia Artificial
Un paseo personal por la historia de la IA
Nuria Oliver, PhD
Directora Cientifica ELLIS Alicante
Lo hemos asumido: las máquinas nos superan a nosotros, sus creadores, incluso en tareas asociadas a la capacidad de estrategia y a la intuición. ¿Cómo lo han conseguido? ¿Significa que pueden pensar como nosotros? A todo esto, ¿cómo pensamos nosotros? El esfuerzo por crear cerebros no biológicos parte de la reflexión sobre el pensamiento y el aprendizaje humanos, e incluye ambiciosas visiones futuristas; pruebas para detectar inteligencia; y procesadores y algoritmos capaces de analizar, dar sentido y aprender a partir de cantidades ingentes de datos, entre otros elementos. El éxito, en última instancia, curiosamente depende de la capacidad de otorgar a los errores el valor (matemático) que se merecen.
Aunque la Inteligencia Artificial (IA) parezca algo novedoso, el desarrollo de máquinas capaces de pensar o dotadas de algunas capacidades humanas ha cautivado nuestro interés desde la antigüedad. Los primeros autómatas --robots antropomorfos-- que imitaban movimientos humanos fueron construidos hace milenios.
Según la Ilíada, Hefesto --el dios griego del fuego y la forja-- creó dos mujeres artificiales de oro con "sentido en sus entrañas, fuerza y voz" que lo liberaban de parte de su trabajo, es decir, creó robots para que lo ayudaran, lo cual lo convierte en todo un adelantado a su tiempo. Heron de Alejandría en el siglo I escribió Automata, donde describe máquinas capaces de realizar tareas automáticamente, como estatuas que sirven vino o puertas que se abren solas. Otros ejemplos incluyen autómatas con fines religiosos, como las figuras mecánicas de los dioses en el Antiguo Egipto, operadas por sacerdotes para sorprender a la multitud; y también lúdicos: las famosas cabezas parlantes y autómatas de la Edad Media, el Renacimiento y el siglo XVIII.
Más allá de la automatización, el ser humano siempre ha sentido curiosidad por explicar y entender la mente humana para, entre otros motivos, construir una mente artificial. Hace más de 700 años, Ramon Llull --beato y filósofo mallorquín patrón de los informáticos-- describió en su Ars Magna (1315) la creación del Ars Generalis Ultima, un artefacto mecánico capaz de analizar y validar o invalidar teorías utilizando la lógica: un sistema de Inteligencia Artificial.
La creadora, en el siglo XIX, del primer algoritmo destinado a ser procesado por una máquina --en otras palabras, el primer programa informático-- fue la matemática Ada Byron (Lovelace). Su visión de que las máquinas podrían servir para algo más que para hacer cálculos matemáticos convirtió a Byron en la primera persona en proponer el uso de la máquina analítica de Babbage para resolver problemas complejos. La máquina de Babbage, no obstante, con sus previstos treinta metros de largo por diez de ancho, nunca llegó a construirse. Se la considera el primer diseño de un computador de propósito general, pero los obstáculos técnicos y la falta de respaldo político --en parte por miedo a un posible uso bélico-- no permitieron convertirla en realidad.
Una conversación inteligente
El mito y la ficción literaria respecto a la Inteligencia Artificial empezaron a materializarse a partir de los años cuarenta del siglo XX, con los primeros ordenadores.
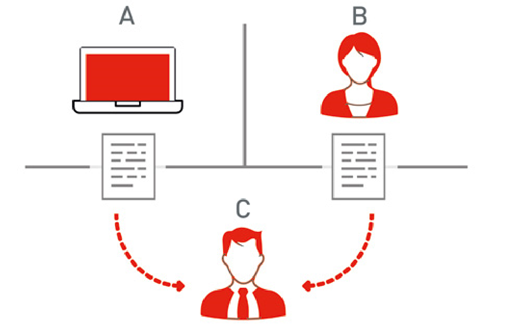
El genial matemático e informático inglés Alan Turing es considerado el padre de la Inteligencia Artificial. Habló de ella en el legendario artículo Computing Machinery and Intelligence, publicado en 1950. Es en este trabajo donde propone la famosa prueba de Turing, ilustrada en la Figura 1, para determinar si un sistema artificial es inteligente.
El ejercicio consiste en que un humano (C en la figura), conocido como el interrogador, interacciona vía texto con un sistema al que puede hacer preguntas. Si el humano no logra discernir cuándo su interlocutor es una máquina (A en la figura), y cuándo otra persona (B en la figura), entonces el sistema supera la prueba de Turing: es inteligente.
La década fundacional para la Inteligencia Artificial fue la de los cincuenta. En 1951 el profesor Marvin Minsky --a quien tuve el honor de conocer en el MIT-- construyó la primera red neuronal computacional como parte de su doctorado en la Universidad de Princeton. Se trataba de una máquina con válvulas, tubos y motores que emulaba el funcionamiento de neuronas interconectadas, y lograba simular el comportamiento de ratas que aprenden a orientarse en un laberinto. La máquina, con sus 40 neuronas, fue uno de los primeros dispositivos electrónicos construidos con capacidad de aprender.
Apenas cinco años más tarde, en 1956, tuvo lugar la mítica convención de Dartmouth (New Hampshire, EE. UU.), en la que participaron figuras legendarias de la informática como John McCarthy, Marvin Minsky, Claude Shannon, Herbert Simon y Allen Newell, todos ellos ganadores del premio Turing, el más prestigioso en computación, equivalente al Nobel --galardón que, además, ganó Simon--.
Dartmouth marca un hito porque es en este encuentro donde se define la Inteligencia Artificial y se establecen las bases para su desarrollo, identificando preguntas clave que incluso hoy día nos sirven de mapa conceptual a los investigadores en esta área (Ver recuadro Las siete cuestiones fundacionales de la IA).
Es en Dartmouth donde McCarthy acuña el término de Inteligencia Artificial, para referirse a "la disciplina dentro de la Informática o la Ingeniería que se ocupa del diseño de sistemas inteligentes", esto es, sistemas con la capacidad de realizar funciones asociadas a la inteligencia humana como percibir, aprender, entender, adaptarse, razonar e interactuar imitando un comportamiento humano inteligente.
¿Algún gato en la imagen?
McCarthy quiso diferenciar la Inteligencia Artificial del concepto de cibernética, impulsado por Norbert Wiener --también profesor del MIT--, y en el que los sistemas inteligentes se basan en el reconocimiento de patrones, la estadística, y las teorías de control y de la información. McCarthy, en cambio, quería enfatizar la conexión de la Inteligencia Artificial con la lógica. Esta diferencia dio lugar a dos escuelas distintas dentro del desarrollo de la IA, como explico más adelante.
Para conseguir que un ordenador aprenda, por ejemplo, a identificar gatos en imágenes, podemos usar distintas estrategias. La aproximación basada en la estadística y en el reconocimiento de patrones requiere mostrar al ordenador miles de fotos con gatos y sin gatos --llamamos a estos ejemplos datos de entrenamiento anotados--; así, proporcionamos a los algoritmos de reconocimiento de patrones la información que necesitan para aprender a identificar automáticamente los patrones recurrentes en las fotos con gatos, versus en las fotos sin gatos. Una vez estos algoritmos han sido entrenados con suficientes ejemplos, serán capaces de determinar si hay o no un gato en las fotos nuevas que les sean presentadas.
La aproximación basada en la lógica conllevaría la definición de una taxonomía de los animales; dentro de estos, de los mamíferos; dentro de estos, de los felinos; y dentro de estos, de los gatos, describiendo sus características. Este conocimiento, programado en el ordenador, tendría que ser lo suficientemente rico, preciso y flexible como para permitir a la máquina localizar en las imágenes las características que definen a un gato, y detectar su presencia.
En un guiño del destino, la propuesta intelectual de Wiener --basada en datos y estadística-- se ha convertido en la dominante en la Inteligencia Artificial, pero utilizando la terminología de McCarthy. Sin embargo, no adelantemos acontecimientos.

Aprendiendo a distinguir entre izquierda y derecha
Entre las más controvertidas y citadas declaraciones realizadas en los albores de la Inteligencia Artificial se cuentan las del psicólogo Frank Rosenblatt, creador del Perceptrón en el Laboratorio Aeronáutico de Cornell. El Perceptrón se presentó a la prensa en 1958, como un programa instalado en un ordenador de IBM, el 704, que por cierto ocupaba una estancia entera.
Según la crónica publicada el 8 de julio de 1958 en el New York Times, el Perceptrón habría de convertirse en "el primer ordenador capaz de pensar como el cerebro humano", equivocándose al principio, pero "volviéndose más sabio con la experiencia". Rosenblatt --señala el Times-- lo describió como el "embrión" de un ordenador en el futuro capaz de "caminar, hablar, ver, escribir, reproducirse y ser consciente de su existencia".
Fue un apreciable ejercicio de extrapolación, teniendo en cuenta que la única habilidad que el Perceptrón mostró a los medios fue aprender a distinguir entre izquierda y derecha. Al 704 se le introducían dos tarjetas, una con marcas en el lado izquierdo y la otra en el derecho; la computadora empezaba a distinguir una tarjeta de otra al cabo de 50 intentos. Rosenblatt explicó que el avance se debía a un cambio en el programa autoinducido por el propio programa, lo que implica aprendizaje.
Más tarde el Perceptrón se implementó en un dispositivo propio, el Perceptrón Mark 1 (ilustrado en la Figura 4), que se aplicaba al análisis de imágenes. Rosenblatt estaba convencido que la máquina reproducía de manera simplificada el funcionamiento de neuronas que trabajan estableciendo conexiones, llamadas sinapsis, con otras neuronas.
Como puede observarse en la Figura 3, el Perceptrón recibe un conjunto de valores de entrada que multiplica cada valor de entrada por un coeficiente determinado al que llamamos peso, o W1j, W2j, etc... de weight en inglés en la Figura, que representa la fuerza de la sinapsis con cada neurona adyacente; y produce una salida: 1 si la suma de las entradas moduladas por sus pesos es superior a un cierto valor, y 0 si es inferior. Las salidas 1 y 0 representan la activación o no de la neurona.
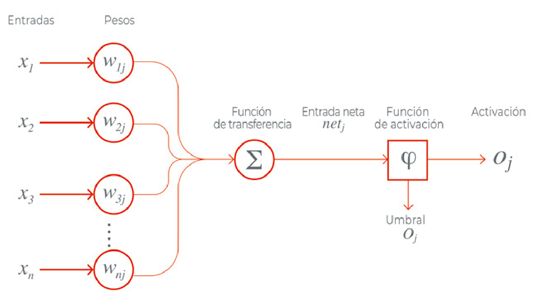
El modelo está basado en un trabajo anterior de Warren McCulloch y Walter Pitts, que demostraron que un modelo de neurona como el descrito puede representar funciones de OR/ AND/NOT. Este resultado era importante porque, como hemos explicado, en los albores de la IA se pensaba que cuando los ordenadores pudieran llevar a cabo operaciones de razonamiento lógico formal, se conseguiría la Inteligencia Artificial.

Aprender a partir de reglas, o de la experiencia
Desde las dos aproximaciones distintas a la Inteligencia Artificial por parte de Wiener (basada en datos) y McCarthy (basada en la lógica), ha existido cierto enfrentamiento entre dos escuelas de pensamiento en la Inteligencia Artificial: el enfoque simbólico-lógico o top-down -originalmente llamado neat-; y el enfoque basado en datos, conexionista o bottom-up -originalmente conocido como scruffy-.
Son abordajes muy distintos conceptualmente. El simbólico, topdown --en inglés, de arriba a abajo--, postulaba que las máquinas, para razonar, debían seguir un conjunto de reglas predefinidas y unos principios de la lógica. La idea es programar en la máquina el conocimiento que poseemos los humanos, de forma que después, aplicando las reglas que también han sido enseñadas previamente, el ordenador pueda derivar conocimiento nuevo.
El ejemplo canónico son los llamados sistemas expertos, el primer ejemplo comercial de la Inteligencia Artificial. Hablaremos de ellos más adelante.
Por su parte la escuela bottom-up --de abajo a arriba-- proponía que la Inteligencia Artificial debía inspirarse en la biología, aprendiendo a partir de la observación y de la interacción con el mundo físico, esto es, de la experiencia. Según este enfoque, si aspiramos a crear IA debemos proporcionar a los ordenadores observaciones de las que aprender. Esto conlleva entrenar algoritmos a partir de miles de ejemplos de lo que queremos que aprendan.
En los sistemas de Inteligencia Artificial suele tomarse como referencia la inteligencia humana. Del mismo modo que la inteligencia humana es diversa y múltiple, la Inteligencia Artificial es una disciplina con numerosas ramas de conocimiento, que se nutren de las dos grandes escuelas de pensamiento top-down y bottom-up.
La escuela simbólico-lógica incluye, entre otras, áreas como la teoría de juegos; la lógica; la optimización; el razonamiento y la representación del conocimiento; la planificación automática; y la teoría del aprendizaje.
En la escuela bottom-up destacaría la percepción computacional -- una de mis áreas de especialidad, que abarca el procesamiento de imágenes, vídeos, texto, audio y datos de otro tipo de sensores--; el aprendizaje automático estadístico --machine learning, otra de mis áreas--; el aprendizaje con refuerzo; los métodos de búsqueda --de texto, imágenes, vídeos--; los sistemas de agentes; la robótica; el razonamiento con incertidumbre; la colaboración humano-IA; los sistemas de recomendación y personalización; y las inteligencias social y emocional computacionales.
Primera era dorada: los sistemas expertos
Mis trabajos de investigación dentro de la IA se enmarcan en el enfoque bottom-up. Inicialmente esta escuela no tuvo mucho éxito práctico, ya que no había disponibles grandes cantidades de datos, ni la capacidad de computación necesaria para entrenar modelos suficientemente complejos como para resultar útiles. Por ello la primera aplicación práctica de la Inteligencia Artificial fue en los años 60, con los sistemas expertos, que pertenecen al enfoque simbólicológico.
En 1956, después de la convención de Dartmouth, Herbert Simon predijo que "en veinte años, las máquinas serán capaces de hacer el trabajo de una persona". Marvin Minsky, por su parte, declaró en 1970 a la revista Life que "dentro de tres a ocho años tendremos una máquina con la inteligencia general de un ser humano". Hasta mediados de los años setenta predominó el optimismo en todo lo relativo a la Inteligencia Artificial y su impacto.
De hecho, el periodo entre 1956 y 1974 suele conocerse como la primera etapa dorada de la Inteligencia Artificial. Fueron los años en que Edward Feigenbaum --uno de los fundadores del departamento de informática de la Universidad de Stanford-- lideró el equipo que construyó el primer sistema experto, implementado en LISP, el programa de ordenador desarrollado por McCarthy.
El nombre de este sistema experto era DENDRAL, y fue fruto del deseo del biólogo molecular Joshua Lederberg, también de Stanford, de disponer de un sistema que facilitara su investigación sobre compuestos químicos en el espacio. DENDRAL ayudaba a los químicos orgánicos a identificar moléculas desconocidas a partir de su espectro de masas, gracias a que le había sido transferido el conocimiento de un prestigioso químico --en concreto Carl Djerassi, creador de la píldora anticonceptiva--. DENDRAL era experto en química porque atesoraba el conocimiento químico y la experiencia de un humano experto en este campo.
Arrecia el 'primer invierno'
Pero a principios de los 70 llegó el invierno, el primer invierno de la IA. Las ambiciosas expectativas creadas durante las dos décadas anteriores no se cumplieron. Además, en 1969 fue publicado el libro Perceptrons, de Minsky y Seymour Papert, a quienes tuve el honor de conocer durante mis años en el MIT. Esta obra contribuyó a desinflar aún más el interés por los modelos bottom-up y, en particular, por las redes neuronales.
En Perceptrons se demostraba que los perceptrones eran muy limitados porque solo pueden aprender funciones extremadamente simples o, expresado en términos más matemáticos, funciones linealmente separables.
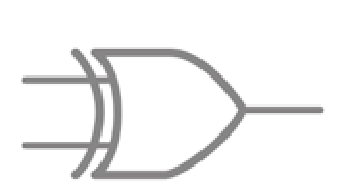
Desgraciadamente, la gran mayoría de los problemas del mundo real son complejos, y no cumplen la condición de ser linealmente separables. En concreto, Minsky y Papert mostraban que los perceptrones no aprenden ni siquiera la función XOR, ilustrada en la Figura 6, que es la más sencilla de las que no pueden separarse con una línea.
La función XOR (de exclusive OR en inglés, o disyunción exclusiva) es una operación lógica que es 1 solo cuando los valores de entrada son distintos (es decir 1 y 0, o 0 y 1), y es 0 cuando los valores de entrada son iguales (1 y 1 o 0 y 0). En términos generales, XOR devuelve un 1 cuando tiene un número impar de valores de entrada que valen 1, y devuelve 0 en caso contrario.
Pese a su sencillez, XOR no es linealmente separable: si representamos los valores (0,0) (1,1) (0,1) y (1,0) en un gráfico, es imposible separar con una recta el (0,0) (1,1) del (0,1) (1,0) para reflejar que XOR devuelve 0 para (0,0) (1,1) y devuelve 1 para (0,1) (1,0). Para poder representar XOR, o cualquier otra función no linealmente separable, se necesitan modelos más complejos que un simple perceptrón.
Por tanto, los investigadores en Inteligencia Artificial se encontraron con limitaciones y dificultades insalvables en la década de los 70. La escasa capacidad de computación de las máquinas impedía procesar grandes cantidades de datos, algo indispensable para entrenar modelos complejos con que abordar problemas reales. Hace apenas una década, o poco más, que hemos comenzado a solventar este reto.
Dichas limitaciones, combinadas con grandes expectativas incumplidas, dieron lugar a un declive tanto en el interés como en la financiación de la Inteligencia Artificial durante el periodo entre 1974 y 1980. El invierno había llegado.
El inasible sentido común
Pero tarde o temprano llega la primavera. El interés por la Inteligencia Artificial, y los fondos disponibles para su desarrollo, empezaron a aumentar de nuevo a principios de los 80. Durante esa década llegaron al mercado los primeros sistemas expertos, con éxito apreciable. En 1985 el gasto en sistemas de IA en las empresas era de miles de millones de dólares.
Dentro del acercamiento simbólico-lógico, en 1984 nació el primer esfuerzo científico por implementar en una máquina el razonamiento de sentido común, mediante una gigantesca base de datos con todo el conocimiento sobre el mundo que tiene, de media, una persona. Llamado Cyc, hoy en día sigue activo en la compañía Cycorp y atesora decenas de millones de aserciones, reglas o ideas del sentido común aportadas por humanos --por ejemplo, el agua causa humedad y la humedad pudre la comida--, que pueden ser usadas por otros programas.
Sin embargo, de nuevo aparecieron obstáculos. Durante el congreso de 1984 de la Asociación Americana de Inteligencia Artificial, Minsky y Roger Schank alertaron de que el entusiasmo y la inversión en Inteligencia Artificial conducirían a una nueva decepción. En efecto, en 1987 comenzó el segundo invierno de la Inteligencia Artificial, que alcanzaría su momento más oscuro en 1990.
Mientras tanto la comunidad científica seguía avanzando en las dos escuelas de pensamiento. Uno de los hitos más importantes de la estrategia bottom-up y, en particular, del conexionismo, fue el uso del algoritmo de backpropagation por parte de David Rumelhart, Geoffrey Hinton y Ronald Williams [1] en 1986.
Entrenando máquinas a partir de datos: el resurgir del conexionismo
Gracias al algoritmo de backpropagation es posible entrenar redes mucho más complejas que el Perceptrón, con numerosas capas de neuronas ocultas --llamadas así en la jerga-- operando entre las capas de entrada y salida y con capacidad, esta vez sí, de modelar problemas complejos. Hoy en día el algoritmo de backpropagation es la base de la gran mayoría de modelos de redes neuronales profundas.
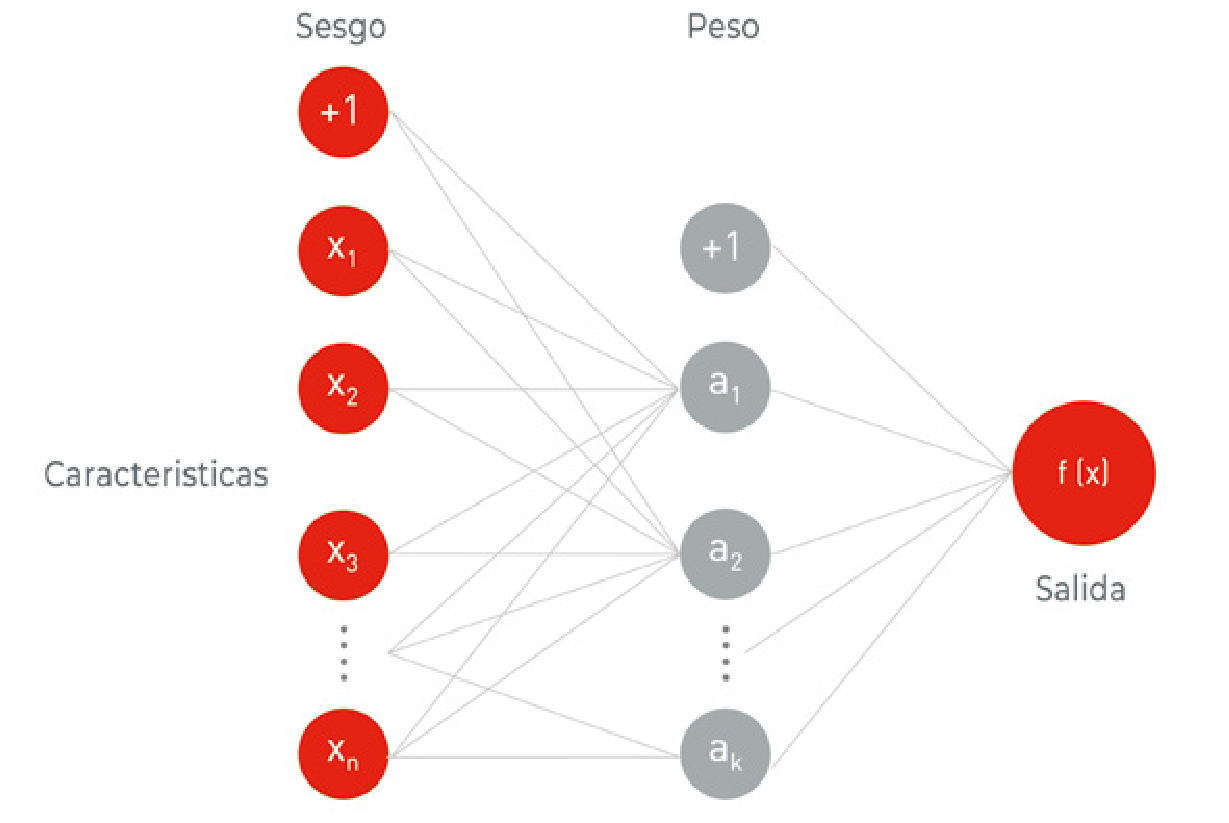
El funcionamiento, en términos muy básicos, es el siguiente. Las redes nacen ignorantes, no saben nada sobre el problema que tienen que resolver a partir de los datos que se les van a proporcionar --volviendo al ejemplo de los gatos, no saben si hay o no un gato en la foto--, pero se lanzan y hacen una predicción; esa predicción es cotejada con la realidad, y se mide su grado de error. En función de esta medida se ajustan los pesos en la red, es decir, los coeficientes que deben ser procesados por la neurona.
Se llama backpropagation porque se propagan los errores hacia atrás en la red, desde las neuronas de salida (las que están más a la derecha en la Figura 7), a las neuronas de entrada. Por tanto, los errores que comete la red neuronal al entrenarse sirven, gracias al algoritmo backpropagation, para determinar los valores de los pesos que lograrían reducir tales errores. Es un proceso iterativo: en cada iteración se van ajustando los pesos en función de los errores cometidos, de forma que estos, y la propia corrección a que se les debe someter, se van reduciendo (ver ejemplo en la Figura 8).
Aunque Rumelhart, Hinton y Williams no fueron los primeros en publicar un artículo sobre backpropagation, fue su trabajo el que logró calar en la comunidad científica por la claridad con que presenta esta idea.
Igualmente cabe destacar el trabajo de Judea Pearl a finales de los 80, cuando incorporó a la Inteligencia Artificial las teorías de la probabilidad y de la decisión. Algunos de los nuevos métodos propuestos incluyen modelos clave en mi investigación, como las redes bayesianas (una red bayesiana es un modelo gráfico probabilístico que representa una serie de variables y sus dependencias probabilísticas en forma de un gráfico donde los nodos son las variables, y las conexiones entre nodos representan las dependencias entre variables) y los modelos ocultos de Markov (un modelo estadístico de un sistema dinámico que puede representarse como la red bayesiana dinámica más sencilla), así como la teoría de la información, el modelado estocástico y la optimización. También se desarrollaron los algoritmos evolutivos, inspirados en conceptos de la evolución biológica como la reproducción, las mutaciones, la recombinación de genes y la selección.
En los algoritmos evolutivos se generan soluciones candidatas al problema que se quiere resolver. Cada solución juega el papel de un individuo en una población; se van seleccionando las soluciones de mayor calidad aplicando ciertos criterios predefinidos, y estas soluciones se hacen evolucionar aplicando los conceptos anteriores de reproducción, mutaciones, etcétera.
El objetivo es que, tras un cierto número de generaciones, las soluciones encontradas sean cada vez mejores. La ventaja es que estos algoritmos se pueden aplicar para resolver multitud de problemas. La desventaja es su complejidad computacional, que dificulta su aplicación a muchos problemas reales.
Desde mediados de los años 90, precisamente cuando comencé mi doctorado en el MIT, hasta hoy en día --y especialmente en la última década--, se ha producido un avance muy significativo en las técnicas de aprendizaje estadístico por ordenador basadas en datos (statistical machine learning), que pertenecen al enfoque bottom-up.
El acceso a cantidades ingentes de datos --Big Data--; la disponibilidad de procesadores muy potentes a bajo coste; y el desarrollo de redes neuronales profundas y complejas, los modelos llamados de deep learning [2] (ver Figuras 8 y 9), son los tres factores que han confluido para instalar hoy día a la Inteligencia Artificial en una "primavera perpetua", en palabras del profesor de la Universidad de Stanford Andrew Ng, con quien también coincidí en MIT.
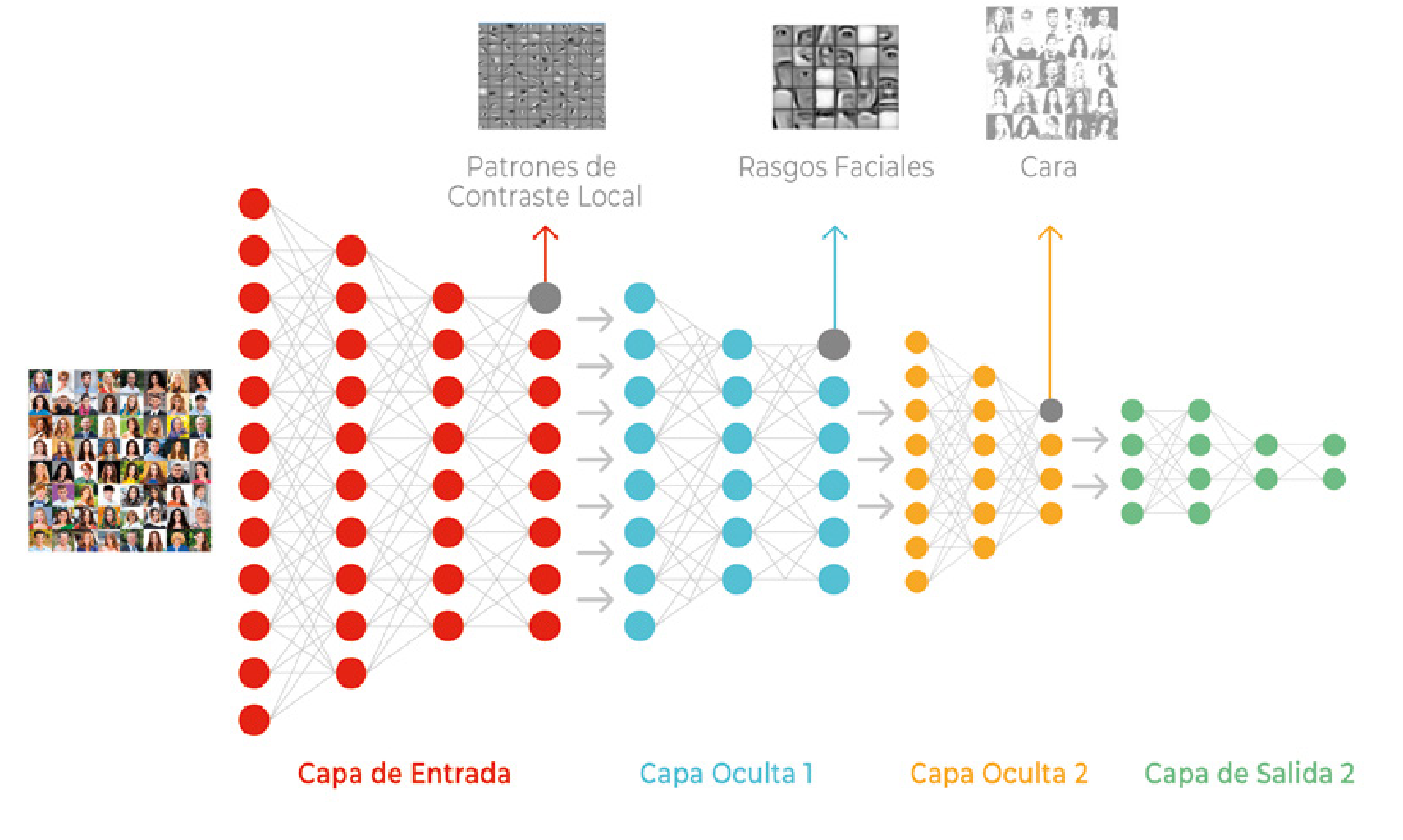
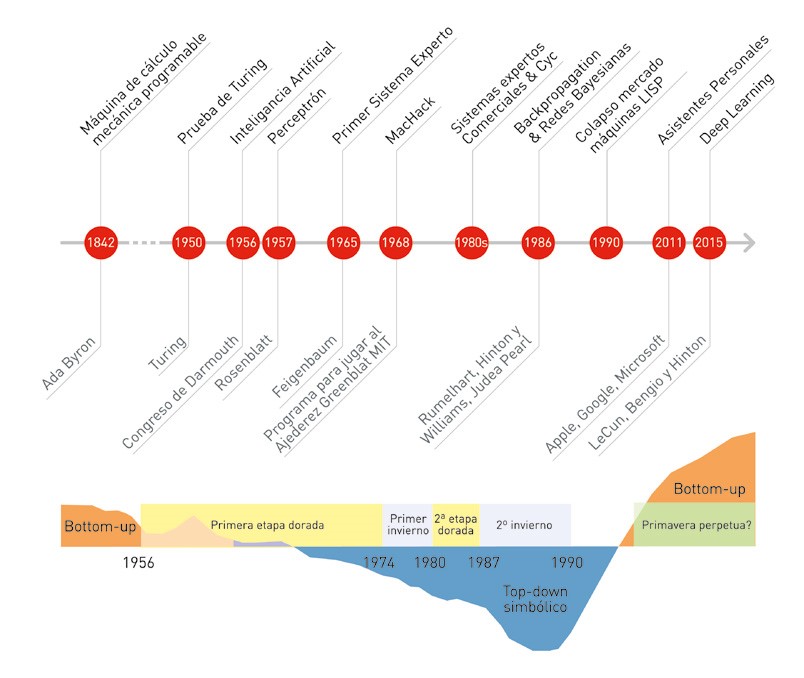
En los últimos años --como puede observarse en la Figura 10--, con el éxito de los métodos de aprendizaje de deep learning se ha producido un fuerte resurgir del acercamiento bottomup y en particular del conexionismo, dentro de la Inteligencia Artificial. Así lo atestigua el hecho de que los pioneros del deep learning Yoshua Bengio, Geoffrey Hinton y Yann LeCun hayan recibido en 2019 el premio Turing, el equivalente al Nobel en informática.
La Inteligencia Artificial --no queda ya alguna duda-- forma parte de nuestro presente. De ello hablaremos a continuación.
LAS SIETE CUESTIONES FUNDACIONALES DE LA IA
En 1955, investigadores pioneros en Inteligencia Artificial propusieron analizar en la Conferencia de Dartmouth (New Hampshire, EE.UU.) la conjetura de que, en principio, todos los aspectos del aprendizaje humano, y en general de la inteligencia, pueden ser descritos de manera lo bastante precisa como para que una máquina pueda simularlas. Desmenuzaron en siete cuestiones el desafío de lograr una Inteligencia Artificial, muchas de las cuales perduran hoy en día como retos a abordar:
- Capacidad computacional: "La velocidad y memoria de los ordenadores actuales podría ser insuficiente para simular muchas de las funciones superiores del cerebro humano, pero el principal obstáculo no es la falta de capacidad de las máquinas, sino nuestra incapacidad para programar (...)", escribieron John McCarthy, Marvin Minsky, Claude Shannon y Herbert Simon.
- Lenguaje. Los humanos, en gran parte, usamos palabras para pensar. ¿Se puede programar a un ordenador para que tenga lenguaje --y pueda, por ejemplo, integrar términos nuevos en frases con significado, como hacemos nosotros--?
- Capacidad de abstracción en las redes neuronales: ¿Cómo se puede disponer una red de hipotéticas neuronas para lograr que formen conceptos?
- ¿Es eficiente esta manera de resolver el problema? Los expertos echaban en falta un método para dimensionar una operación computacional, para decidir si abordarla o por el contrario buscar otras estrategias.
- Superarse a uno mismo. "Probablemente una máquina verdaderamente inteligente llevará a cabo tareas que pueden ser descritas como de superación personal".
- Pensamiento abstracto. "Puede valer la pena hacer un intento de clasificar las abstracciones, y describir métodos por los que las máquinas podrían generar abstracciones a partir de estímulos sensoriales y otros datos".
- Aleatoriedad y creatividad. "Una conjetura atractiva, y sin embargo claramente incompleta, es que la diferencia entre el pensamiento creativo y el pensamiento competente poco imaginativo reside en la introducción de una cierta aleatoriedad".
Preguntas frequentes
John McCarthy, junto con Alan Turing, Marvin Minsky, Nathaniel Rochester y Claude E. Shannon acuñaron el término "inteligencia artificial" en una propuesta que escribieron para la famosa conferencia de Dartmouth en el verano de 1956. Esta conferencia inició la IA como una disciplina.
En 1951 el profesor Marvin Minsky construyó la primera red neuronal computacional (SNARC) como parte de su doctorado en la Universidad de Princeton. Se trataba de una máquina con válvulas, tubos y motores que emulaba el funcionamiento de neuronas interconectadas, y lograba simular el comportamiento de ratas que aprenden a orientarse en un laberinto. La máquina, con sus 40 neuronas, fue uno de los primeros dispositivos electrónicos construidos con capacidad de aprender.
Alan Turing, el genial matemático e informático inglés considerado el padre de la Inteligencia Artificial, propuso en 1950 una pregunta fascinante en su legendario artículo Computing Machinery and Intelligence: ¿cómo sabemos si una máquina es inteligente? Su respuesta fue elegante: pongámosla a conversar. El ejercicio consiste en que un humano interactúa vía texto con un sistema, haciéndole preguntas. Si el humano no logra discernir cuándo su interlocutor es una máquina y cuándo otra persona, entonces el sistema supera la prueba de Turing: es inteligente. Simple y brillante.
Dartmouth marca un hito porque es en este encuentro, celebrado en el verano de 1956 en New Hampshire, donde nace la Inteligencia Artificial como disciplina. Imagina reunir en una habitación a figuras legendarias como John McCarthy, Marvin Minsky, Claude Shannon, Herbert Simon y Allen Newell. Todos ellos acabarían ganando el premio Turing, el equivalente al Nobel en computación. En Dartmouth se definió la IA y se establecieron las bases para su desarrollo, identificando siete cuestiones fundacionales que incluso hoy día sirven de mapa conceptual a los investigadores en esta área.
Desde los albores de la IA ha existido cierto enfrentamiento entre dos escuelas de pensamiento. El enfoque simbólico-lógico o top-down --de arriba a abajo-- postula que las máquinas deben seguir reglas predefinidas. La idea es programar en la máquina el conocimiento humano y las reglas de la lógica. Por su parte, la escuela conexionista o bottom-up --de abajo a arriba-- propone que la IA debe inspirarse en la biología, aprendiendo a partir de la observación y la experiencia. Curiosamente, en un guiño del destino, la propuesta de Wiener basada en datos y estadística se ha convertido en la dominante, pero utilizando la terminología de McCarthy.
Los sistemas expertos fueron la primera aplicación práctica de la Inteligencia Artificial, surgida en los años 60. Son fascinantes: imagina poder transferir todo el conocimiento y experiencia de un químico prestigioso a un programa de ordenador. Eso fue exactamente DENDRAL, el primer sistema experto creado por Edward Feigenbaum en Stanford. El sistema ayudaba a químicos a identificar moléculas desconocidas porque atesoraba el conocimiento de Carl Djerassi, el creador de la píldora anticonceptiva. DENDRAL era experto en química porque contenía el conocimiento químico de un humano experto en este campo. Fue la era dorada del enfoque simbólico-lógico.
Tarde o temprano llega el invierno cuando las expectativas no se cumplen. El primer invierno (1974-1980) llegó cuando los investigadores se toparon con limitaciones insalvables: los perceptrones eran muy limitados, la capacidad de computación era escasa, y las predicciones optimistas de los años 50 y 60 --como que en 1970 tendríamos máquinas con la inteligencia de un ser humano-- resultaron ser exageradas. El segundo invierno (1987-1990) vino cuando los sistemas expertos mostraron sus limitaciones y, de nuevo, las expectativas chocaron con la realidad. Minsky y Schank alertaron en 1984 que el entusiasmo conduciría a una nueva decepción, y tenían razón. Estos inviernos, aunque dolorosos, fueron necesarios para ajustar expectativas y desarrollar nuevas aproximaciones.
El backpropagation o retropropagación es uno de los hitos más importantes del enfoque conexionista. Desarrollado por David Rumelhart, Geoffrey Hinton y Ronald Williams en 1986, este algoritmo permite entrenar redes mucho más complejas que el Perceptrón, con numerosas capas de neuronas ocultas operando entre las capas de entrada y salida. ¿Cómo funciona? Las redes nacen ignorantes y hacen predicciones; esas predicciones se cotejan con la realidad y se mide el error. Entonces --y aquí está la magia-- se propagan los errores hacia atrás en la red, ajustando los pesos de cada neurona de forma iterativa. Los errores que comete la red se convierten en un regalo para aprender. Hoy día es la base de la gran mayoría de modelos de deep learning.
Desde mediados de los años noventa, y especialmente en la última década, se ha producido un avance extraordinario. Tres factores han confluido para instalar hoy día a la Inteligencia Artificial en una "primavera perpetua", en palabras de Andrew Ng: el acceso a cantidades ingentes de datos --lo que llamamos Big Data--; la disponibilidad de procesadores muy potentes a bajo coste; y el desarrollo de redes neuronales profundas y complejas, los modelos de deep learning. Inicialmente el enfoque bottom-up no tuvo mucho éxito práctico porque no había datos ni computación. Pero ahora sí, y eso lo ha cambiado todo.