
IA hoy en día
La IA ya transforma nuestras vidas
Si la electricidad impulsó la Segunda Revolución Industrial, e internet y los ordenadores personales la Tercera, la Inteligencia Artificial está provocando la Cuarta. Los sistemas de IA están transformando la medicina, el transporte, el sector energético, nuestra elección de contenidos de cultura y ocio, la economía en su conjunto y por supuesto la ciencia, a pasos agigantados. Pese a sus limitaciones, y a que queda aún muy lejos el sueño de una inteligencia equiparable a la humana, todo apunta a que en poco tiempo el planeta estará envuelto en un sistema circulatorio que lo irrigará capilarmente con Inteligencia Artificial.
"Soy un ser humano. Me asusto cuando veo algo que supera con mucho mi capacidad de comprensión", declaró el campeón mundial de ajedrez Gary Kasparov tras su derrota contra el programa Deep Blue, de IBM, el 11 de mayo de 1997[1]. Era la primera vez que un campeón de ajedrez perdía contra una máquina. "Enérgica y brutalmente, el ordenador Deep Blue de IBM arrebató a la humanidad, al menos temporalmente, el puesto de mejor ajedrecista del planeta", decía el New York Times al inicio de su crónica.
La gran repercusión mediática de este logro de la Inteligencia Artificial, impensable hace solo tres décadas, ha contribuido al exorbitante aumento en el interés por esta disciplina.
Pero hay muchos más hitos. En 2005 un vehículo autónomo desarrollado en la Universidad de Stanford, EE. UU., recorrió autónomamente 212 kilómetros en el desierto y se convirtió así en el primero en superar el DARPA Grand Challenge[2], una carrera de vehículos sin conductor creada solo un año antes por la Agencia de Investigación en Proyectos Avanzados de Defensa estadounidense, más conocida por su acrónimo DARPA. Este hito demostró que la conducción autónoma era posible y fue el punto de partida de los miles de millones de dólares de inversión en la conducción sin conductor.
Poco más tarde, en 2011, el programa de IA Watson, de IBM, venció a dos de los campeones humanos del concurso estadounidense de preguntas y respuestas Jeopardy![3]. Ese fue el año en que muchos de nosotros empezamos a hablar con asistentes personales instalados en nuestros teléfonos móviles --Siri, Cortana y Google Now--, programas que permiten a sus usuarios utilizar la voz y el lenguaje natural para hacer preguntas y dar instrucciones, y que desde 2015 están también en nuestro hogar --Alexa, Google Home--.
En 2016 otro enfrentamiento hombre-máquina, con victoria para el contendiente no biológico, conquistó portadas en todo el planeta.
El programa AlphaGo, desarrollado por la compañía DeepMind, de Google, venció en el juego chino Go a uno de los mejores jugadores humanos del mundo, Lee Sedol[4]. Las reglas del Go son más simples que las del ajedrez, pero el número de configuraciones a tener en cuenta es mucho mayor. Además, el juego requiere grandes dosis de intuición, por lo que dominarlo parecía del todo imposible para una máquina. AlphaGo solo pudo lograrlo recurriendo a su capacidad de aprendizaje, mucho más desarrollada que la de Deep Blue.
También aprendió mucho el programa de la Universidad Carnegie Mellon Libratus cuando, en enero de 2017, se enfrentó al póker a cuatro de los mejores jugadores del mundo. Al concluir veinte días de torneo las ganancias de Libratus superaban en 1,7 millones de dólares las de los humanos[5]. Fue una victoria relevante, porque el póker representa un nivel adicional de complejidad: en el ajedrez y en el Go el tablero, con todas sus piezas, es visible para ambos jugadores, mientras que en el póker desconocemos las cartas de nuestros contrincantes, que, además, pueden marcarse faroles. Es decir, el póker es un juego de información incompleta y por tanto mucho más difícil de jugar computacionalmente.
Otros hitos recientes se producen en los combates máquinamáquina. En diciembre de 2017 AlphaZero, de DeepMind, no solo venció al mejor jugador de ajedrez del mundo --que por cierto es un programa de ordenador llamado Stockfish--, sino que hizo gala de su capacidad de aprender el juego por sí solo[6]. Ambos programas se enfrentaron en una serie de cien partidas, de las que AlphaZero ganó 28 y el resto quedaron en tablas; para lograr la hazaña, al programa de DeepMind le bastó conocer las reglas del ajedrez y dedicar cuatro horas a entrenarse, jugando contra sí mismo millones de veces.
No menos relevante es que un sistema de procesamiento de lenguaje desarrollado por Alibaba --la gran compañía china de comercio electrónico-- superara en 2018 los resultados de los humanos en la prueba de comprensión lectora de la Universidad de Stanford (EE. UU.)[7]. El Stanford Question Answering Dataset es un conjunto de cien mil preguntas, que hacen referencia a más de 500 artículos de Wikipedia.
En la salud, el ocio, la seguridad, la economía...
Más allá de estos hitos, que pueden parecer alejados de la aplicación práctica, la Inteligencia Artificial ocupa ya un lugar importante en multitud de esferas de nuestra vida. Convivimos con la IA probablemente sin saberlo. Está presente en los sistemas de búsqueda y recomendación de información, contenido, productos o amigos que utilizamos en nuestro día a día, como Netflix, Spotify, Facebook, y en cualquier servicio de noticias o de búsqueda en internet. También en las aplicaciones para la cámara del móvil que detectan automáticamente las caras en las fotos; en los asistentes personales de móviles y hogares; en chatbots conversacionales; y en las ciudades inteligentes, para por ejemplo predecir el tráfico.
La IA interviene en la compraventa de acciones, la adjudicación de créditos, la contratación de seguros y la fijación de tarifas, entre otras muchas decisiones que marcan el ritmo de los mercados financieros y las empresas. En el ámbito de la salud funcionan ya los sistemas de diagnóstico automático a partir de historiales clínicos, así como programas de análisis de imágenes médicas, para asistir el diagnóstico radiológico, y de ADN, para por ejemplo detectar mutaciones o variantes genéticas asociadas a enfermedades.
La toma de decisiones de las Administraciones Públicas se apoya igualmente en la Inteligencia Artificial, con sistemas de vigilancia, de soporte a decisiones judiciales o de clasificación y jerarquización del alumnado. Numerosas aplicaciones se destinan al ámbito de la seguridad y la defensa, desde en el control de viajeros en las fronteras y la adjudicación de visados, hasta para fabricar armas autónomas.
La industria, y en general los procesos productivos, llevan décadas utilizando robots industriales, al igual que sistemas de planificación y predicción de la demanda o de la producción.
Y, por supuesto, sin el apoyo de la Inteligencia Artificial no podríamos soñar con tener vehículos autónomos, una predicción meteorológica certera a medio plazo ni, en general, avances en numerosas áreas de conocimiento. La IA empieza a convertirse en un actor importante de la investigación científica, interviniendo en modelos físicos de toda clase de fenómenos y procesos, en la predicción de la estructura tridimensional de las proteínas, en el diseño de fármacos... La lista es larga.
No hay duda de que la IA tiene un potencial inmenso para construir una sociedad mejor, y ese es el motor de mi trabajo.
El sustrato físico
Si en la evolución humana el aumento de la capacidad cognitiva va de la mano de cambios biológicos, también la inteligencia de las máquinas depende del sustrato físico en que se implementa. No solo de software vive la Inteligencia Artificial. En el desarrollo de la IA, tanto en sus aplicaciones prácticas como en la consecución de los hitos antes descritos, han tenido un papel clave los avances en el hardware, en particular en los sistemas de procesamiento y almacenamiento a gran escala, distribuidos y en paralelo.
Sin los potentes procesadores actuales tampoco existirían hoy los complejos modelos de deep learning o aprendizaje profundo, basados en redes neuronales con muchas capas de procesado de información (ver Figuras 9 y 10). Es el nuevo hardware, a menudo
optimizado para esta tarea específica, el que permite entrenar a los modelos, alimentándolos con grandes cantidades de datos en un tiempo y con un consumo energético razonables.
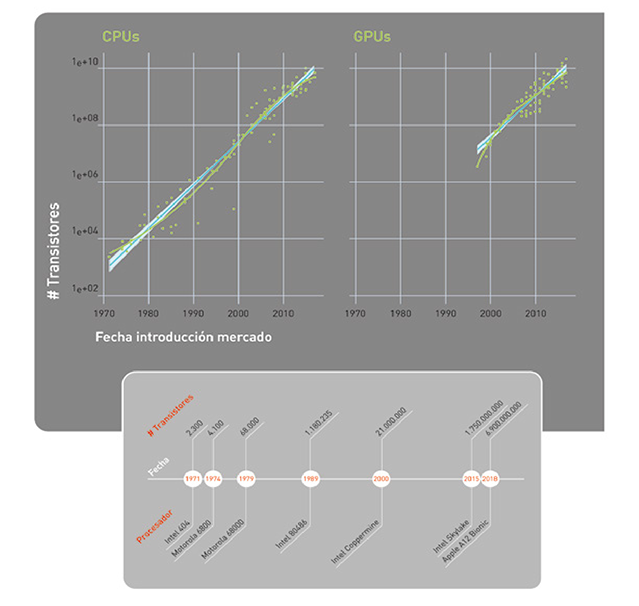
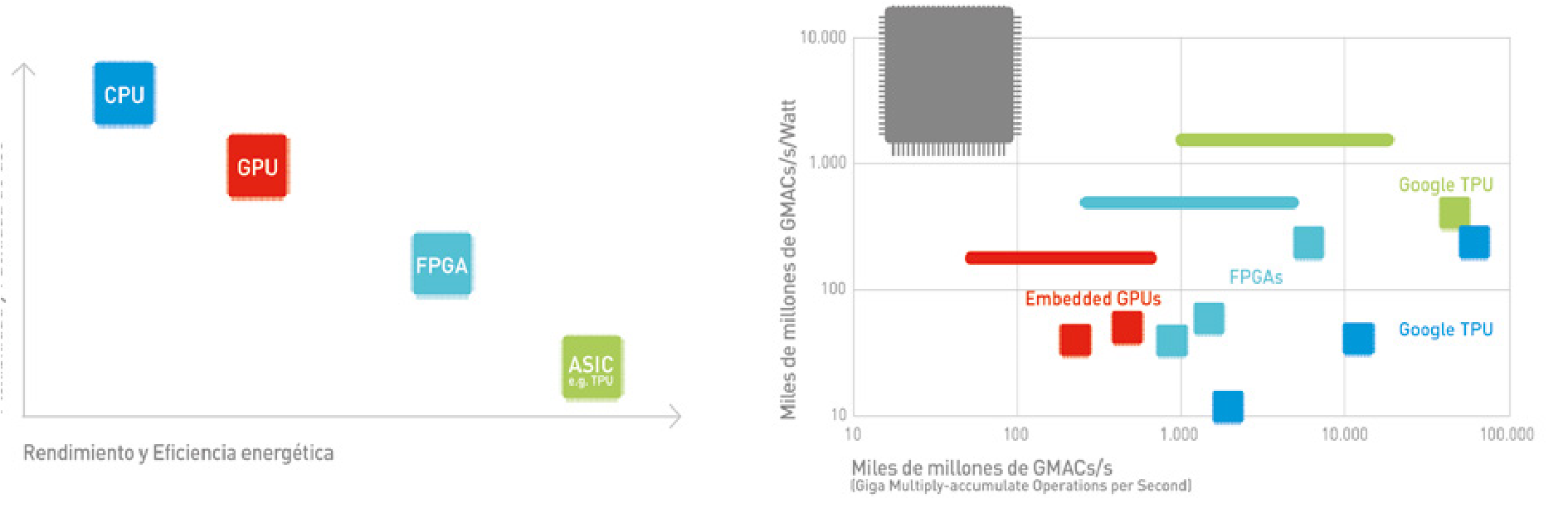
En los últimos años hemos pasado de utilizar procesadores de propósito general (CPUs y GPUs o graphics processing units) a procesadores especializados, optimizados para este tipo de modelos de IA (FPGAs o field-programmable gate arrays y ASICs o application-specific integrated circuits, como la TPU desarrollada por Google). Las figuras 11 y 12 ilustran la evolución en la capacidad de computación. La Figura 11 muestra la famosa Ley de Moore desde 1971, según la cual el número de transistores que podemos integrar en un circuito por el mismo precio se duplica cada año, o año y medio.
La parte de la izquierda representa la Ley de Moore en CPUs, y la derecha en GPUs. En la Figura 12 se ve dónde se sitúan los distintos tipos de procesadores en función de su flexibilidad y facilidad de uso, versus su eficiencia energética y rendimiento.
El lector interesado puede encontrar un resumen de los principales procesadores utilizados para el aprendizaje automático en [8]. Tampoco podemos obviar que transmitir y procesar las enormes cantidades de datos con que se trabaja hoy día requiere un elevadísimo consumo energético (Ver recuadro ¿Un planeta inteligente poco sostenible?).
¿UN PLANETA INTELIGENTE PERO POCO SOSTENIBLE?
El consumo energético de la Inteligencia Artificial representa un desafío creciente para la sostenibilidad del planeta. Los centros de datos y sistemas de IA requieren cantidades masivas de electricidad, tanto para el procesamiento como para la refrigeración. Estudios recientes estiman que el entrenamiento de un único modelo grande de IA puede generar más de 550 toneladas de CO~2~ (como en el caso de GPT-3), equivalente a cinco veces las emisiones totales de un automóvil durante toda su vida útil[9]. A medida que la IA se vuelve más ubicua, la necesidad de mejorar drásticamente la eficiencia energética de los procesadores y desarrollar fuentes de energía renovables se vuelve cada vez más urgente para evitar que el progreso tecnológico comprometa nuestros objetivos climáticos.
No podemos obviar la demanda energética que conllevaría una implantación masiva de los sistemas de Inteligencia Artificial. Por ello, y siempre desde la perspectiva del desarrollo y adopción de la Inteligencia Artificial para el bien social, hemos de invertir en investigación e implementación de soluciones que sean sostenibles desde el punto de vista medioambiental.
Necesitamos apoyarnos en algoritmos de Inteligencia Artificial para modelar el clima, por ejemplo, o construir modelos predictivos del cambio climático o del consumo energético. Pero también hemos de considerar el impacto medioambiental del desarrollo de la Inteligencia Artificial.
El campeón de ajedrez que desconoce qué es el ajedrez
El despliegue de los hitos de la Inteligencia Artificial durante la última década puede resultar abrumador, incluso inquietante. Basta una pregunta para ganar perspectiva y reconsiderar la situación: ¿sabe Libratus que está jugando --y ganando-- al póker?
Los sistemas de Inteligencia Artificial suelen dividirse en tres tipos, atendiendo a su grado de competencia. La IA específica hace referencia a sistemas capaces de realizar una tarea concreta, como jugar al ajedrez, reconocer el habla, imágenes o procesar texto, incluso mejor que un humano. Pero solamente saben hacer esa tarea. Este es el tipo de Inteligencia Artificial que tenemos hoy en día.
Los sistemas con IA general, en cambio, exhiben una inteligencia similar a la humana: múltiple, adaptable, flexible, eficiente, incremental... Esta sería la aspiración última de la Inteligencia Artificial, y estamos aún muy lejos de hacerla realidad.
La tercera categoría corresponde a los sistemas con súper-inteligencia, término un tanto controvertido referido al desarrollo de sistemas con inteligencia superior a la humana, tal y como propone el filósofo de la Universidad de Oxford, Reino Unido, Nick Bostrom [10].
En la actualidad disponemos de sistemas de Inteligencia Artificial específica, es decir, capaces de realizar automática y autónomamente
una tarea concreta, pero esa y solo esa. Aunque un algoritmo juegue mejor que el mejor de los humanos, es incapaz de hacer cualquier otra tarea. De hecho, tampoco sabe qué es el ajedrez, y tendría dificultades para jugar si introdujéramos cambios en las reglas.
Los sistemas actuales manifiestan un tipo limitado de inteligencia: son incapaces, entre otras cosas, de generalizar y extender a otros ámbitos sus niveles de competencia en una tarea de manera automática, como haría un humano.
Inteligencia Artificial 'versus' Inteligencia Humana
El éxito reciente de los sistemas de Inteligencia Artificial quizás esté desviando la atención respecto al grado de avance en cuestiones profundas del área. Hay problemas fundacionales de la Inteligencia Artificial que todavía están por resolver.
Algunos de estos problemas derivan de tres limitaciones básicas, tres aspectos que marcan la diferencia entre los mecanismos de aprendizaje automático disponibles actualmente y los sistemas inteligentes biológicos. Lo explica Jeff Hawkins en un artículo para IEEE Spectrum [11] que resumo en los siguientes párrafos.
Los sistemas de aprendizaje biológicos --cerebros-- son capaces de aprender rápidamente. Unas pocas observaciones o experiencias táctiles suelen ser suficientes para aprender algo nuevo, a diferencia de los millones de ejemplos que necesitan los sistemas de Inteligencia Artificial actuales.
Además, los sistemas biológicos aprenden de manera incremental, es decir, agregamos conocimiento nuevo sin tener que volver a aprender todo desde cero ni perder conocimiento anterior. Es más, hacemos todo lo anterior de manera continua. Aprendemos conforme interaccionamos con el mundo físico, y nunca dejamos de hacerlo. El aprendizaje rápido, incremental y constante es un elemento esencial que permite a los sistemas biológicos inteligentes adaptarse a un entorno cambiante, y sobrevivir.
La neurona es un elemento clave en el aprendizaje biológico. La complejidad de las neuronas biológicas y sus conexiones es lo que dota al cerebro de la capacidad para aprender. Hoy sabemos que el cerebro tiene plasticidad y que constantemente se están creando nuevas neuronas --el fenómeno llamado neurogénesis-- y sinapsis --sinaptogénesis--. Se estima que diariamente se sustituyen hasta un 40% de las sinapsis en cada neurona, lo que implica que hay en marcha un proceso constante de creación de nuevas conexiones neuronales.
Los sistemas de aprendizaje artificiales no tendrían por qué reproducir exactamente el funcionamiento de las neuronas biológicas, pero esta capacidad para disponer de un aprendizaje rápido, incremental y constante, caracterizado por la destrucción y creación de sinapsis, es esencial.
Otra cuestión clave es que el cerebro procesa la información mediante representaciones distribuidas no densas, o dispersas (sparse distributed representations o SDRs) [12], una terminología referida a que solo un conjunto reducido de neuronas está activo en cada momento del tiempo. Este grupo de neuronas encendidas cambia de un instante a otro en función de lo que haga el ser vivo, pero es en cualquier caso pequeño.
Esta configuración con representaciones distribuidas de la información es robusta respecto a los errores y a la incertidumbre. Además, goza de dos propiedades interesantes: la propiedad del solape, que permite detectar rápidamente si dos percepciones son idénticas o diferentes; y la propiedad de la unión, que permite al cerebro mantener varias representaciones en paralelo.
Por ejemplo, si oímos un animal que se mueve entre unos arbustos, pero no hemos podido verlo, podría ser un conejo, una ardilla o una rata. Dado que las representaciones en el cerebro son dispersas, nuestro cerebro puede activar tres SDRs al mismo tiempo -la del conejo, la ardilla y la rata- sin interferencias entre ellas. Gracias a esta propiedad de poder unir SDRs el cerebro gestiona, opera y toma decisiones aún sin disponer de información completa, es decir, con incertidumbre.
Además, el aprendizaje tiene cuerpo. Nuestro cerebro recibe la información de los distintos sentidos, y esta información cambia según nos movemos y actuamos en nuestro entorno.
Un sistema de Inteligencia Artificial no tiene por qué tener un cuerpo físico, pero sí la capacidad de actuar sobre su entorno físico y virtual, y recibir una reacción --feedback-- a sus acciones. Los sistemas de aprendizaje con refuerzo -reinforcement learning- hacen algo similar, y son instrumentales en la consecución de algunos de los hitos previamente descritos, como los logrados por AlphaZero.
El cerebro es capaz de integrar la información captada por los distintos sentidos y por el sistema motor, para poder no sólo procesar, reconocer y decidir en función de lo percibido, sino también actuar. Esta integración sensorial-motora es básica en el funcionamiento del cerebro y probablemente deberá también serlo en los sistemas de Inteligencia Artificial.
Finalmente, en el cerebro la información sensorial es procesada por un sistema jerárquico: conforme la información va pasando de un nivel a otro se van calculando características cada vez más complejas y abstractas de lo que se está percibiendo.
Los modelos de aprendizaje profundo también utilizan jerarquías, pero mucho más complicadas de las empleadas por el cerebro humano, con decenas o una centena de niveles y centenas o miles de millones de parámetros. Estas redes neuronales profundas --modelos de deep learning-- necesitan millones de observaciones para aprender un patrón. A nuestro cerebro, en cambio, le bastan pocos niveles de jerarquías y también, como ya he dicho, pocos ejemplos para aprender. El cerebro aprende de manera mucho más eficiente que los modelos computacionales de hoy en día.
Estas limitaciones, sin embargo, no están frenando el creciente impacto de la Inteligencia Artificial en nuestras vidas. La IA es ya un elemento integral de la Cuarta Revolución Industrial en la que estamos inmersos.
Podemos imaginar escenarios sin precedente en la historia de la humanidad. Escenarios donde, por ejemplo, una red de sistemas de IA podría muy rápidamente incorporar los últimos métodos computacionales en el diagnóstico de una enfermedad, y desplegarlos a toda la población del planeta. El equivalente analógico, que consistiría en una incorporación casi instantánea del conocimiento a todos los médicos del planeta, es simplemente inviable.
La Cuarta Revolución Industrial
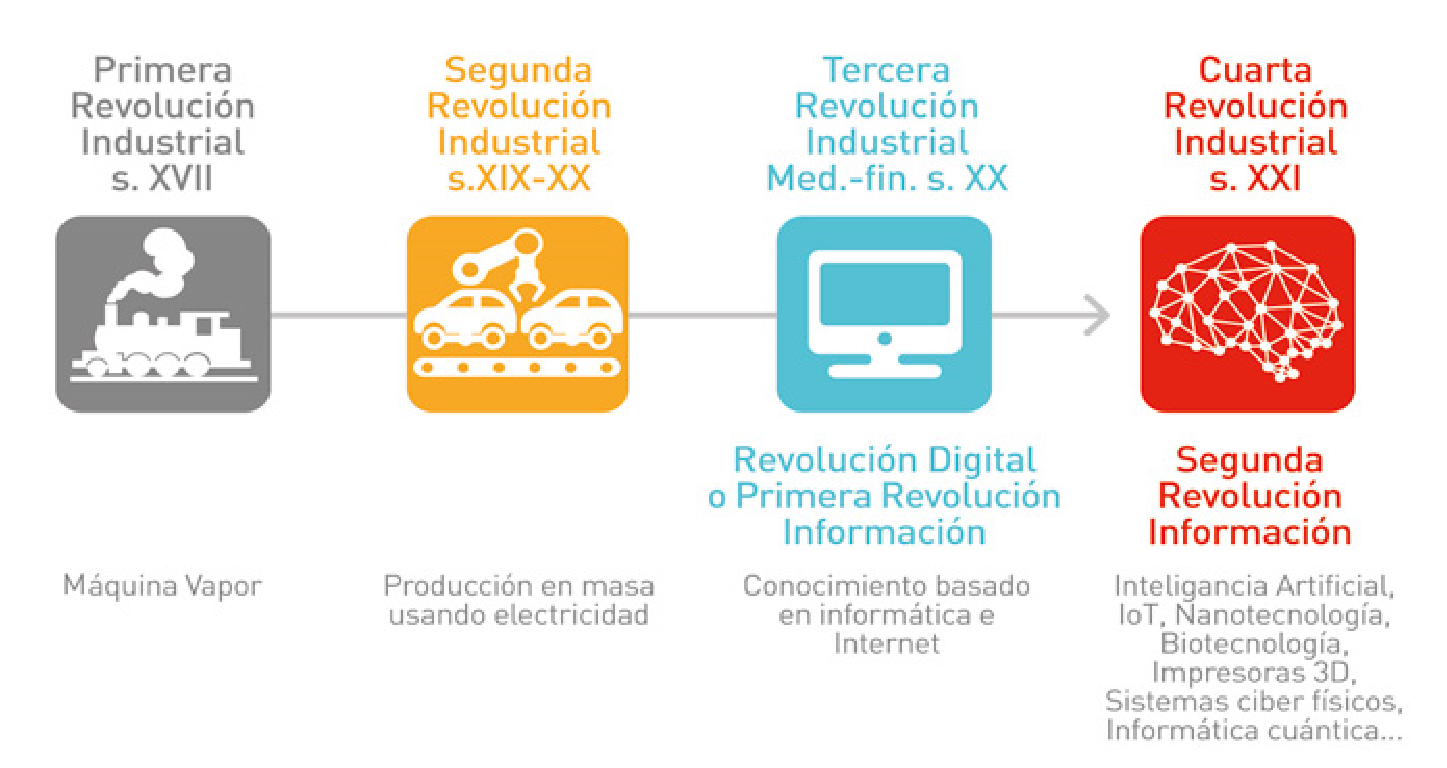
En los últimos tres siglos hemos vivido cuatro revoluciones industriales, ilustradas en la Figura 12. La primera tuvo lugar entre los siglos XVIII y XIX en Europa y Norteamérica, y se corresponde con el momento histórico en que sociedades que eran mayoritariamente agrarias y rurales se convirtieron en industriales y urbanas. El principal factor impulsor de esta revolución fue la invención de la máquina de vapor, junto con el desarrollo de las industrias textil y metalúrgica.
La Segunda Revolución Industrial --conocida como la Revolución Tecnológica-- ocurrió justo antes de la Primera Guerra Mundial, entre 1870 y 1914, y se corresponde con un crecimiento de las industrias anteriores y el desarrollo de otras nuevas, como la del acero y el petróleo, y con la llegada de la electricidad. Los avances tecnológicos más importantes de esta revolución incluyen el teléfono, la bombilla, el fonógrafo y el motor de combustión interna.
La Tercera Revolución Industrial es la Revolución Digital y hace referencia a la transición de dispositivos mecánicos y analógicos al uso de tecnologías digitales. Comenzó en los años 80 y continúa hoy en día. Los avances tecnológicos clave incluyen los ordenadores personales, internet y el desarrollo de otras tecnologías de la información y las comunicaciones (TICs).
Finalmente, la Cuarta Revolución Industrial se apoya en avances de la Revolución Digital, pero incorpora la ubicuidad de la tecnología digital tanto en nuestra sociedad como en nuestro cuerpo, y la unión creciente entre los mundos físico, biológico y digital.
Los avances tecnológicos que hacen posible esta nueva revolución incluyen la robótica, la Inteligencia Artificial --alimentada con Big Data-- la nanotecnología, la biotecnología, la ingeniería genética, el internet de las cosas, los vehículos autónomos, las impresoras en tres dimensiones y la informática cuántica. El término fue presentado y reconocido globalmente durante el Foro Económico Mundial en 2016 por su fundador, el economista alemán Klaus Schwab.
Una IA transversal e invisible
La Inteligencia Artificial tiene un conjunto de características que contribuyen a convertirla en un elemento clave en esta Cuarta Revolución Industrial. Para empezar, es transversal e invisible.
Las técnicas de Inteligencia Artificial, como hemos explicado, pueden utilizarse en un sinfín de aplicaciones en medicina, energía, transporte y educación; en la investigación científica, en los sistemas de producción, la logística, los servicios digitales y la prestación de servicios públicos y privados. Y en la gran mayoría de estas aplicaciones, los sistemas de IA consisten en software instalado en el corazón de aplicaciones y servicios. Es decir, son invisibles. Estas dos propiedades, la transversalidad y la invisibilidad, sitúan a la Inteligencia Artificial en el núcleo de la Cuarta Revolución Industrial, con un papel similar al jugado por la electricidad en la Segunda Revolución Industrial.
Otras características de la IA son la complejidad, la escalabilidad y la actualización constante. Los sistemas actuales de Inteligencia Artificial basados en modelos de aprendizaje profundo son complejos, con cientos de capas de neuronas y millones de parámetros. Esta complejidad tiene un doble filo.
Por una parte, dificulta la interpretación de los modelos, lo que, en ciertas aplicaciones, por ejemplo, en medicina o en educación, es un obstáculo limitante. Pero al mismo tiempo es esta complejidad la que permite a la Inteligencia Artificial procesar cantidades ingentes
de datos, y realizar tareas con niveles de competencia superiores a los de los humanos. Es decir, los complejos modelos de aprendizaje profundo dotan a los sistemas de IA de gran escalabilidad.
En muchos casos solo podemos extraer conocimiento y valor del Big Data a través del uso de sistemas de Inteligencia Artificial, ya que los métodos tradicionales no pueden procesar volúmenes de datos tan grandes que, además, son variados, generados a gran velocidad y no estructurados --es decir, son texto, audio, vídeo, imágenes o proceden de sensores--. Para los sistemas de Inteligencia Artificial esto no es un problema gracias a que son altamente escalables, esto es, consisten fundamentalmente en software que puede estar conectado con miles o millones de otros sistemas de IA, dando lugar a una red colectiva.
Hoy en día, sin IA seríamos incapaces de analizar e interpretar las enormes cantidades de texto, imágenes, audio o vídeo que existen. Entre otras cosas, no podríamos buscar información en internet. En astronomía, física, biología, química, meteorología o medicina cada vez generamos más datos, datos a los que, por su complejidad y volumen, tampoco podríamos sacar partido. Algo similar sucede en la economía y las finanzas, en el comercio electrónico o en el transporte, por citar otras áreas. Básicamente, cualquier aplicación que se beneficie del análisis de grandes cantidades de datos no estructurados es susceptible de ser transformada por la IA.
La capacidad de actualizar el software de manera masiva es también una propiedad clave. Combinada con la escalabilidad, la actualización
masiva permite a la IA tener impacto en la vida de cientos o incluso miles de millones de personas en poco tiempo.
Otra propiedad definitoria de la IA es su habilidad para predecir. Los sistemas de Inteligencia Artificial pueden utilizarse para la toma de decisiones automáticas y para predecir situaciones futuras. De hecho, aspiramos a que las decisiones algorítmicas basadas en IA entrenada con datos carezcan de las limitaciones de las decisiones humanas -- conflictos de interés, sesgos, intereses propios, corrupción...--, y sean por tanto más justas y objetivas.
Sin embargo, esto no será necesariamente así si ignoramos las limitaciones de las decisiones que toman los algoritmos, como explicaré posteriormente.
Ni ciencia ficción, ni moda
La presencia de la IA en nuestras vidas, y su capacidad para mejorar la sociedad, son innegables. Las grandes potencias mundiales --tanto empresas como gobiernos-- han comprendido que el liderazgo en Inteligencia Artificial debe ser no solo económico, sino también político y social.
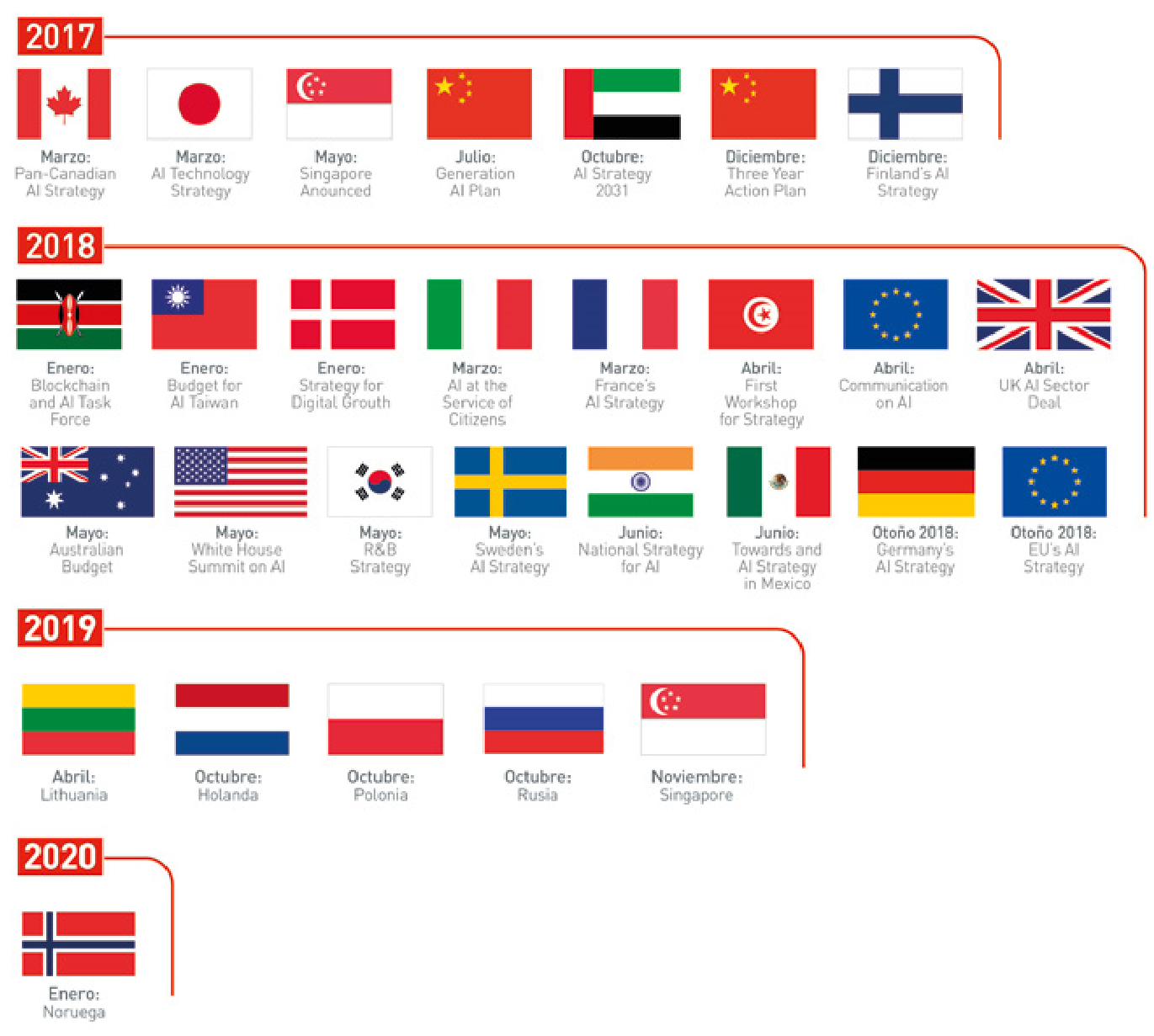
Por eso en los últimos dos años los gobiernos de más de una veintena de países --incluyendo EE. UU., China, Canadá, Francia, Taiwán, Singapur, México, Suecia, India, Australia y Finlandia-- han elaborado estrategias nacionales sobre Inteligencia Artificial, tal y como refleja la Figura 14.
En Europa, el grupo de expertos sobre IA creado por la Comisión Europea --del que soy miembro reserva-- publicó en 2019 un conjunto de guías éticas para la Inteligencia Artificial y unas recomendaciones sobre inversiones y políticas en IA. Esta estrategia europea propone actuaciones conjuntas para una cooperación más estrecha y eficiente entre los Estados miembros, Noruega, Suiza y la Comisión en cuatro ámbitos clave: aumentar la inversión, lograr que haya más datos disponibles (para entrenar a los algoritmos de IA), fomentar
el talento y garantizar la confianza. En febrero de 2020, la Comisión Europea publicó un Libro Blanco sobre Inteligencia Artificial[13], que sentó las bases para la regulación. Posteriormente, en abril de 2021, la Comisión propuso el Reglamento de Inteligencia Artificial (AI Act)[14], la primera normativa integral sobre IA a nivel mundial, que fue finalmente adoptado por el Parlamento Europeo en marzo de 2024 y entró en vigor el 1 de agosto de 2024[15], estableciendo un marco regulatorio basado en riesgos para aplicaciones de IA, especialmente aquellas con impacto en la vida de las personas, como la salud o el transporte.
El entonces vicepresidente de la Comisión, el estonio Andrus Ansip, afirmaba en una nota de prensa: "Hemos acordado colaborar a fin de reunir datos --la materia prima de la Inteligencia Artificial-- en sectores como la asistencia sanitaria para mejorar el diagnóstico y el tratamiento del cáncer. Tendremos que actuar coordinadamente para lograr el objetivo de inversiones públicas y privadas de al menos 20.000 millones de euros, algo fundamental para el crecimiento y el empleo. La Inteligencia Artificial no es un capricho, es nuestro futuro".
Esta inversión anual en I+D dedicada a la IA de 20.000 millones de euros anuales en el periodo 2021-2027 es necesaria para reducir la brecha entre la inversión en IA de Europa --de entre 3.000 y 15.000 millones de euros--, y la de Asia y Norteamérica. La Comisión propone un reparto de esfuerzos de inversión entre diferentes actores europeos para conseguir alcanzar la inversión mencionada: 1.000 millones al año serían a cargo de programas de I+D (Horizon Europe y Europa Digital); los Estados miembros invertirían 6.000 millones anuales, parte de los cuales podría proceder de fondos europeos; y 13.000 millones de euros deberían proceder del sector privado.
En febrero de 2020, la Comisión Europea publicó tres documentos estratégicos en el contexto de la Inteligencia Artificial.
En primer lugar, un libro blanco[16] sobre Inteligencia Artificial donde la Comisión Europea presenta un marco para el desarrollo de una Inteligencia Artificial confiable, basada en la excelencia y la confianza. Este documento propone la definición de reglas claras en aplicaciones de alto riesgo de la Inteligencia Artificial, incluyendo la salud, el transporte o la policía. El objetivo es garantizar que los sistemas de IA son transparentes, supervisados por humanos y susceptibles de ser evaluados y certificados por autoridades externas. También se incluye la necesidad de asegurar que los datos con los que se entrenan estos sistemas no tienen sesgos y que siempre se respetan los derechos fundamentales. En el caso de aplicaciones de la IA de bajo riesgo, la Comisión Europea propone un esquema de etiquetado voluntario.
En segundo lugar, la Estrategia de Datos[17] aspira a crear un único mercado europeo para datos que asegure la competitividad de Europa y la soberanía de sus datos.
En tercer lugar, un documento con recomendaciones por parte del grupo de alto nivel de "Business to Government Data Sharing"[18] , que incluye la adopción de medidas legislativas sobre la gobernanza de los datos, el acceso y su reutilización para el interés público.
En cuanto a los Estados miembros, numerosos países han publicado sus estrategias nacionales de IA acompañadas de ambiciosos compromisos presupuestarios: Alemania estableció en 2018 una estrategia dotada con 3.000 millones de euros hasta 2025, ampliada en 2020 con 2.000 millones adicionales hasta alcanzar un total acumulado de 5.000 millones para el periodo 2018-2025[19], habiendo ejecutado 3.380 millones hasta 2024; Francia implementó su estrategia en tres fases con inversión pública progresiva (1.500 millones en 2018-2022, 560 millones en 2022-2025, y 2.500 millones desde 2025), y además consiguió atraer 109.000 millones de euros en compromisos de inversión privada anunciados en la Cumbre de IA de París de febrero de 2025[20]; Finlandia comprometió 100 millones anuales a partir de 2019; y España, tras su primera Estrategia Nacional de IA de 2020 con 600 millones para 2021-2023, aprobó en mayo de 2024 una Estrategia actualizada con 1.500 millones adicionales para 2024-2025[21], sumando un total de 2.100 millones entre 2021-2025, financiados principalmente por el Plan de Recuperación europeo.
Además, algunos Gobiernos, como el británico, han creado sus propias organizaciones de Inteligencia Artificial (Office of AI, Office of Ethics in AI), con carácter transversal, para maximizar el impacto de la IA y acelerar su desarrollo y adopción.
La OCDE probó en mayo de 2019 una Recomendación sobre Inteligencia Artificial [22] a la que se han adherido 36 países miembros y seis países no miembros.
En España se creó un comité de nueve expertos multidisciplinares en 2017, para la elaboración de un libro blanco sobre el Big Data y la IA con recomendaciones estratégicas. Tras la publicación de una estrategia de I+D+i en IA en junio de 2019, el presidente Pedro Sánchez presentó en diciembre de 2020 la primera Estrategia Nacional de Inteligencia Artificial con una inversión de 600 millones de euros para el periodo 2021-2023[23]. Posteriormente, en mayo de 2024, el Gobierno aprobó una Estrategia actualizada[21:1] que añade 1.500 millones de euros adicionales para 2024-2025, sumando un total de 2.100 millones entre 2021-2025, financiados principalmente por el Plan de Recuperación, Transformación y Resiliencia europeo. La estrategia actualizada incluye inversiones significativas en supercomputación (90 millones de euros para el superordenador MareNostrum), desarrollo de talento (760 millones de euros en áreas de investigación y formación especializada), y apoyo al sector privado (400 millones de euros a través del Fondo NextTech y 350 millones en el programa Kit Digital).
Curiosamente, dos comunidades autónomas han asumido cierto liderazgo en IA y han publicado sus estrategias: Cataluña y la Comunidad Valenciana[24].
Sin embargo, como consecuencia de algunas de las características descritas anteriormente, la IA no estará necesariamente distribuida de manera homogénea o justa en la sociedad. Esto significa que la IA plantea retos que debemos afrontar con rigor y ambición, si queremos una Inteligencia Artificial por y para la sociedad. El siguiente capítulo se centra en analizar estos retos, y en proponer soluciones.
- Lenguaje. - Los sistemas de procesamiento del lenguaje natural aún necesitan incorporar semántica y razonamiento. Es decir, falta conocimiento semántico en los sistemas que procesan e interpretan el lenguaje natural.
- Incertidumbre. - Los seres vivos somos capaces de tomar decisiones en entornos de incertidumbre, con falta de información. Pero la incertidumbre es compleja de modelar matemáticamente, lo que da lugar a modelos que no son resolubles computacionalmente.
- Aprendizaje a corto, medio y largo plazo. - La gran mayoría de los sistemas de aprendizaje por ordenador son entrenados en una fase inicial, utilizando datos de entrenamiento que sirven para determinar automáticamente los valores de los parámetros de los modelos. Una vez el modelo ha aprendido, se puede aplicar a datos nuevos. Sin embargo, los sistemas inteligentes biológicos aprenden constantemente y con diferentes horizontes temporales --corto, medio y largo plazo--, algo aún no al alcance de los sistemas de aprendizaje computacionales.
- Causalidad.- Este concepto es una abstracción para ayudarnos a explicar cómo funciona el mundo, y forma parte del aprendizaje temprano de nuestra y otras especies. Sin embargo, la gran mayoría de los modelos computacionales de aprendizaje estadístico aprenden y detectan correlaciones entre variables y factores, no relaciones de causalidad. La capacidad para inferir automáticamente la causalidad es un área activa de investigación.
- Contexto.- Los modelos entrenados con datos aprenden de la información contenida en dichos datos, que no son más que un reflejo parcial de una realidad compleja. Sin información adicional -no captada por los datos-, los modelos pueden llegar a conclusiones erróneas. Por ello es importante entender qué información de contexto puede no estar siendo captada por los datos con que se entrena un determinado modelo.
- Aprendizaje constante.- Los seres vivos aprendemos constante, incremental y asociativamente, en lugar de solamente durante la fase de entrenamiento de los modelos.
- Robustez.- Los modelos no deben fallar estrepitosamente si se cambian ciertas características en los datos de entrada, como sucede hoy en día. Por ejemplo, hoy podemos engañar a redes neuronales que reconocen objetos en imágenes agregando a la imagen ruido que es imperceptible para los humanos, pero que confunde totalmente a la red neuronal, de manera que en lugar de reconocer que en la foto hay un oso panda, la red neuronal piensa que hay un mono. Este tipo de ataques a los modelos de aprendizaje se conoce como aprendizaje adversarial (adversarial machine learning).
Preguntas frequentes
"Soy un ser humano. Me asusto cuando veo algo que supera con mucho mi capacidad de comprensión", declaró Gary Kasparov tras su derrota. El 11 de mayo de 1997, Deep Blue de IBM hizo historia: era la primera vez que una máquina vencía a un campeón mundial de ajedrez en un partido oficial. "Enérgica y brutalmente, el ordenador arrebató a la humanidad el puesto de mejor ajedrecista del planeta", decía el New York Times. La repercusión mediática fue enorme, impensable solo tres décadas antes. Lo hemos asumido: las máquinas nos superan incluso en tareas asociadas a la estrategia y la intuición.
En 2016 otro enfrentamiento hombre-máquina, con victoria para el contendiente no biológico, conquistó portadas en todo el planeta. AlphaGo, desarrollado por DeepMind de Google, venció en el juego chino Go a Lee Sedol, uno de los mejores jugadores humanos del mundo. ¿Por qué fue tan impresionante? El Go tiene reglas más simples que el ajedrez, pero el número de configuraciones a tener en cuenta es mucho mayor. Además, requiere grandes dosis de intuición, por lo que dominarlo parecía del todo imposible para una máquina. AlphaGo solo pudo lograrlo recurriendo a su capacidad de aprendizaje mediante deep learning, mucho más desarrollada que la de Deep Blue.
Si la electricidad impulsó la Segunda Revolución Industrial, e internet y los ordenadores personales la Tercera, la Inteligencia Artificial está provocando la Cuarta. Los sistemas de IA están transformando la medicina, el transporte, el sector energético, nuestra elección de contenidos de cultura y ocio, la economía en su conjunto y por supuesto la ciencia, a pasos agigantados. Pese a sus limitaciones, y a que queda aún muy lejos el sueño de una inteligencia equiparable a la humana, todo apunta a que en poco tiempo el planeta estará envuelto en un sistema circulatorio que lo irrigará capilarmente con Inteligencia Artificial.
La Ley de Moore, formulada en 1965, ha guiado el desarrollo de procesadores durante décadas. Predice que el número de transistores que podemos integrar en un circuito por el mismo precio se duplica cada año, o año y medio. Esta evolución exponencial ha sido fundamental para el desarrollo de la IA moderna. Sin los potentes procesadores actuales tampoco existirían hoy los complejos modelos de deep learning, basados en redes neuronales con muchas capas de procesado de información. Es el nuevo hardware el que permite entrenar a los modelos, alimentándolos con grandes cantidades de datos en un tiempo y con un consumo energético razonables.
En los últimos años hemos pasado de utilizar procesadores de propósito general (CPUs y GPUs o graphics processing units) a procesadores especializados, optimizados para modelos de IA. Las GPUs, originalmente diseñadas para gráficos, resultaron ser muy eficientes para el procesamiento paralelo necesario en redes neuronales. Luego llegaron los FPGAs (field-programmable gate arrays) y ASICs (application-specific integrated circuits), como la TPU desarrollada por Google. Cada tipo tiene su lugar: las CPUs son flexibles y fáciles de usar, mientras que las TPUs ofrecen mayor eficiencia energética y rendimiento para tareas específicas de IA. Es un equilibrio entre versatilidad y especialización.
En 2011 muchos de nosotros empezamos a hablar con asistentes personales instalados en nuestros teléfonos móviles --Siri, Cortana y Google Now--, programas que permiten utilizar la voz y el lenguaje natural para hacer preguntas y dar instrucciones. Desde 2015 están también en nuestro hogar --Alexa, Google Home--. Estos sistemas combinan procesamiento de lenguaje natural, reconocimiento de voz y aprendizaje automático. Lo fascinante es cómo han evolucionado: cada vez nos entienden mejor, anticipan nuestras necesidades, y la interacción se vuelve más natural. Forman ya parte de nuestra vida cotidiana.
Convivimos con la IA probablemente sin saberlo. Está presente en los sistemas de búsqueda y recomendación que utilizamos cada día: Netflix nos sugiere qué ver, Spotify qué escuchar, Facebook a quién seguir. Está en las aplicaciones de la cámara del móvil que detectan automáticamente las caras en las fotos. En las ciudades inteligentes que predicen el tráfico. En el ámbito de la salud funcionan ya sistemas de diagnóstico automático a partir de historiales clínicos y de análisis de imágenes médicas. La IA interviene en la compraventa de acciones, la adjudicación de créditos, la contratación de seguros. Y por supuesto, sin ella no podríamos soñar con vehículos autónomos ni con avances en numerosas áreas de conocimiento. La lista es larga y crece cada día.
Referencias
IBM Deep Blue vs. Garry Kasparov, 11 de mayo de 1997. Fue la primera vez que un campeón mundial de ajedrez perdía contra una máquina en un match oficial. History.com: "Deep Blue defeats Garry Kasparov in chess match" (mayo 1997). https://www.history.com/this-day-in-history/may-11/deep-blue-defeats-garry-kasparov-in-chess-match ↩︎
Stanford Racing Team's autonomous vehicle "Stanley" ganó el DARPA Grand Challenge 2005, completando 212 km (132 millas) en el desierto de Mojave en 6 horas y 53 minutos, convirtiéndose en el primer vehículo autónomo en completar el desafío. Smithsonian Magazine: "How a Blue SUV Named Stanley Revolutionized Driverless Car Technology" https://www.smithsonianmag.com/smithsonian-institution/how-a-blue-suv-named-stanley-revolutionized-driverless-car-technology-180984882/ ↩︎
IBM Watson venció a los campeones de Jeopardy! Brad Rutter y Ken Jennings en febrero de 2011, ganando el primer premio de $1 millón. CNN: "IBM's Watson Jeopardy supercomputer beats humans" (enero 2011). https://money.cnn.com/2011/01/13/technology/ibm_jeopardy_watson/ ↩︎
AlphaGo de DeepMind derrotó a Lee Sedol, campeón mundial de Go, por 4-1 en marzo de 2016 en Seúl, Corea del Sur. El match fue visto por más de 200 millones de personas. Nature: "The Go Files: AI computer wraps up 4-1 victory against human champion" (marzo 2016). https://www.nature.com/articles/nature.2016.19575. CNBC: "Google DeepMind's AlphaGo takes on Go champion Lee Sedol" (marzo 2016). https://www.cnbc.com/2016/03/08/google-deepminds-alphago-takes-on-go-champion-lee-sedol-in-ai-milestone-in-seoul.html ↩︎
Libratus de Carnegie Mellon derrotó a cuatro jugadores profesionales de póker en enero de 2017, ganando $1.766.250 en chips en 120.000 manos. Carnegie Mellon University: "Carnegie Mellon Artificial Intelligence Beats Top Poker Pros" (enero 2017). https://www.cmu.edu/news/stories/archives/2017/january/AI-beats-poker-pros.html. Science: "Superhuman AI for heads-up no-limit poker: Libratus beats top professionals" (diciembre 2017). https://www.science.org/doi/10.1126/science.aao1733 ↩︎
AlphaZero de DeepMind derrotó a Stockfish 8 (el mejor programa de ajedrez del mundo) en diciembre de 2017, ganando 28 partidas y empatando 72 de 100 juegos después de solo 4 horas de auto-entrenamiento. DeepMind: "AlphaZero: Shedding new light on chess, shogi, and Go" (diciembre 2017). https://deepmind.google/discover/blog/alphazero-shedding-new-light-on-chess-shogi-and-go/. Chess.com: "Google's AlphaZero Destroys Stockfish In 100-Game Match" (diciembre 2017). https://www.chess.com/news/view/google-s-alphazero-destroys-stockfish-in-100-game-match ↩︎
El sistema de IA de Alibaba superó a los humanos en el Stanford Question Answering Dataset (SQuAD) en enero de 2018, obteniendo 82.44% vs. 82.304% humano en más de 100.000 preguntas sobre 500 artículos de Wikipedia. South China Morning Post: "Alibaba's artificial intelligence bot beats humans in reading" (enero 2018). https://www.scmp.com/tech/china-tech/article/2128243/alibabas-artificial-intelligence-bot-beats-humans-reading-first. World Economic Forum: "These robots beat humans in the Stanford reading test" (enero 2018). https://www.weforum.org/stories/2018/01/these-two-machines-just-beat-humans-on-a-stanford-reading-comprehension-test/ ↩︎
Los procesadores especializados para machine learning han evolucionado desde CPUs y GPUs de propósito general hacia hardware optimizado como FPGAs, ASICs, y TPUs (Tensor Processing Units) de Google. El chip B200 de Nvidia mostró duplicación del rendimiento comparado con el H100. IEEE Spectrum: "Newest Google and Nvidia Chips Speed AI Training" (2023). https://spectrum.ieee.org/ai-training-2669810566. ACM Computing Surveys: "A Survey on Deep Learning Hardware Accelerators for Heterogeneous HPC Platforms" (2024). https://dl.acm.org/doi/10.1145/3729215 ↩︎
El entrenamiento de modelos grandes de IA genera emisiones significativas de CO2. Por ejemplo, el entrenamiento de GPT-3 consumió 1.287 megavatt-horas de electricidad y generó aproximadamente 552 toneladas de dióxido de carbono, según investigación de Google y UC Berkeley. MIT Technology Review: "Training a single AI model can emit as much carbon as five cars in their lifetimes" (junio 2019). https://www.technologyreview.com/2019/06/06/239031/training-a-single-ai-model-can-emit-as-much-carbon-as-five-cars-in-their-lifetimes/. MIT News: "Shrinking deep learning's carbon footprint" (agosto 2020). https://news.mit.edu/2020/shrinking-deep-learning-carbon-footprint-0807 ↩︎
N. Bostrom, «SuperIntelligence: Paths, dangers, strategies, Oxford, UK: Oxford University Press, 2014. J. Hawkins, «What intelligent machines need to learn from the neocortex» IEEE Spectrum, 2017. ↩︎
J. Hawkins, «What intelligent machines need to learn from the neocortex» IEEE Spectrum, 2017. ↩︎
S. Ahmad y J. Hawkins, «Properties of Sparse Distributed Representations and their Application to Hierarchical Temporary Memory,» Arxiv, 2015. ↩︎
Comisión Europea, «White Paper on Artificial Intelligence - A European approach to excellence and trust», febrero 2020. [https://commission.europa.eu/publications/white-paper-artificial-intelligence-european-approach-excellence-and-trust_en] ↩︎
Comisión Europea, «Proposal for a Regulation laying down harmonised rules on artificial intelligence (Artificial Intelligence Act)», abril 2021. [https://artificialintelligenceact.eu/the-act/] ↩︎
Parlamento Europeo y Consejo de la Unión Europea, «Regulation (EU) 2024/1689 on artificial intelligence (AI Act)», julio 2024. Publicado en el Diario Oficial de la UE el 12 de julio de 2024, entrada en vigor el 1 de agosto de 2024. [https://eur-lex.europa.eu/legal-content/EN/TXT/?uri=CELEX:32024R1689] ↩︎
https://ec.europa.eu/info/sites/info/files/commission-white-paper-artificialintelligence-feb2020_en.pdf ↩︎
https://ec.europa.eu/info/strategy/priorities-2019-2024/europe-fit-digitalage/european-data-strategy_en ↩︎
https://ec.europa.eu/digital-single-market/en/news/meetings-expertgroup-business-government-data-sharing ↩︎
Gobierno Federal de Alemania, «AI Strategy», adoptada en 2018 con presupuesto inicial de 3.000 millones de euros (2018-2025), ampliada en junio de 2020 con 2.000 millones adicionales del paquete de estímulo económico, alcanzando un total acumulado de 5.000 millones para el periodo 2018-2025. Según el informe de progreso de la OCDE 2025, se habían ejecutado 3.380 millones hasta 2024. [https://knowledge4policy.ec.europa.eu/ai-watch/germany-ai-strategy-report_en] ↩︎
Gobierno de Francia, «France AI Strategy 2025», febrero 2025. Estrategia pública en tres fases (1.500 millones en 2018-2022, 560 millones en 2022-2025, y 2.500 millones desde 2025). Los 109.000 millones de euros anunciados en la Cumbre de IA de París representan compromisos de inversión del sector privado (no fondos públicos), incluyendo contribuciones de UAE (30-50.000 millones), Brookfield (20.000 millones), Bpifrance (10.000 millones), e Iliad (3.000 millones), principalmente para infraestructura de centros de datos en los próximos cinco años. [https://www.elysee.fr/en/emmanuel-macron/2025/02/11/make-france-an-ai-powerhouse] y [https://techcrunch.com/2025/02/10/macron-unveils-a-112b-ai-investment-package-as-frances-answer-to-stargate/] ↩︎
Gobierno de España, «Estrategia de Inteligencia Artificial 2024», aprobada en Consejo de Ministros el 14 de mayo de 2024. Actualización de la estrategia de 2020 que añade 1.500 millones de euros para 2024-2025, adicionales a los 600 millones ejecutados en 2021-2023, sumando 2.100 millones en total para el periodo 2021-2025, financiados por el Plan de Recuperación, Transformación y Resiliencia (PRTR). [https://www.lamoncloa.gob.es/lang/en/gobierno/councilministers/paginas/2024/20240514-council-press-conference.aspx] ↩︎ ↩︎
OECD. «Recommendation of the Council on Artificial Intelligence». , Pub. L. No. OECD/LEGAL/0449 (2019). [https://legalinstruments.oecd.org/en/instruments/OECD-LEGAL-0449] ↩︎
Gobierno de España, «Estrategia Nacional de Inteligencia Artificial», presentada por el presidente Pedro Sánchez el 2 de diciembre de 2020. Primera estrategia nacional con inversión pública de 600 millones de euros para el periodo 2021-2023, como parte del componente 16 del Plan de Recuperación, Transformación y Resiliencia. [https://www.lamoncloa.gob.es/lang/en/presidente/news/paginas/2020/20201202_enia.aspx] ↩︎
https://participa.gencat.cat/uploads/decidim/attachment/file/818/ Document-Bases-Estrategia-IA-Catalunya.pdf http://www.presidencia.gva.es/documents/80279719/169117420/Dossier_cas.pdf/88361b83-0e33-4b49-99c0-ad894ffc0f75 ↩︎